RDD中的join操作一般是针对RDD[(K, V)]来进行的,用于将各个分区中键相同的元素组织起来。对应的在DataFrame中,也可以进行join操作(像比较常见的SortMergeJoin),它可以避免RDD join使用不当而造成的shuffle。接下来,本文将通过RDD join以及DataFrame SortMergeJoin的过程来解释,为什么RDD join会产生shuffle以及DataFrame SortMergeJoin是通过何种手段来避免shuffle的?
RDD Join
我们可以看到对于key相同的元素,首先会在rdd1中找到相应的元素,比如(1, “a”),然后在遍历rdd2中对应key所有的元素(1, "b"), (1, "c"),最后进行组合List((1,(a,b)), (1,(a,c)), (1,(b,b))),基本流程如下:
scala> val l1 = List((1, "a"), (1, "b"), (2, "b"))
l1: List[(Int, String)] = List((1,a), (1,b), (2,b))
scala> val l2 = List((1, "b"), (1, "c"), (2, "c"))
l2: List[(Int, String)] = List((1,b), (1,c), (2,c))
scala> val rdd1 = sc.parallelize(l1)
scala> val rdd2 = sc.parallelize(l2)
scala> val result = (rdd1 join rdd2).collect
result: org.apache.spark.rdd.RDD[(Int, (String, String))] = MapPartitionsRDD[4] at join at <console>:35
(1,(a,b))
(1,(a,c))
(1,(b,b))
(1,(b,c))
(2,(b,c))
(1) 生成CoGroupedRDD
join操作是建立在cogroup操作之上的,它会将依赖的分区中key相同的元素分别组织在一个buffer中。
scala> val grouped = (rdd1 cogroup rdd2).collect
res6: Array[(Int, (Iterable[String], Iterable[String]))] =
Array((1,(CompactBuffer(a, b),CompactBuffer(b, c))), (2,(CompactBuffer(b),CompactBuffer(c))))
cogroup(otherRDD, partitioner)
coGroupedRDD.compute
// 依次计算CoGroupPartition,需要先计算依赖的父RDD中的分区,涉及到Shuffle
val rddIterators = new ArrayBuffer[(Iterator[Product2[K, Any]], Int)]
(dep, depNum) <- dependencies.zipWithIndex
// 构建存放不同组的map,依赖RDD个数对应Array中CompactBuffer个数
val map = createExternalMap(numRdds)
// 遍历rddIterators中的值,根据depNum将对应的记录放入对应的位置
for ((it, depNum) <- rddIterators) {
map.insertAll {}
}
(2) 对应CoGroupPartition中的CoGroup中元素进行M x N式的组合
val joinViaCoGroup = (rdd1 cogroup rdd2).flatMapValues { pair =>
// CompactBuffer(a, b), CompactBuffer(b, c)
// (scala.Iterable[String], scala.Iterable[String])
for {
v <- pair._1.iterator
w <- pair._2.iterator
} yield (v, w)
}
(1,(a,b))
(1,(a,c))
(1,(b,b))
(1,(b,c))
(2,(b,c))
(3) 关于partitioner的选择
如果参与join的任意一个RDD有partitioner,则会选择那个partitioner,否则就使用HashPartitioner。至于JoinedRDD的分区数,如果spark.default.parallelism设置了,则使用,否则就选择上游RDD中分区数最大的(Unless spark.default.parallelism is set, the number of partitions will be the same as the number of partitions in the largest upstream RDD)。
(4) 关于shuffle
具体的流程可以参见另一篇文章 Spark基础之Shuffle,如果参与join的RDD没有经过处理, 则产生的是ShuffleDependency,那么计算ResultRDD分区时,就需要从多个父RDD分区取数据,通过下图可以更直观的了解这一流程。
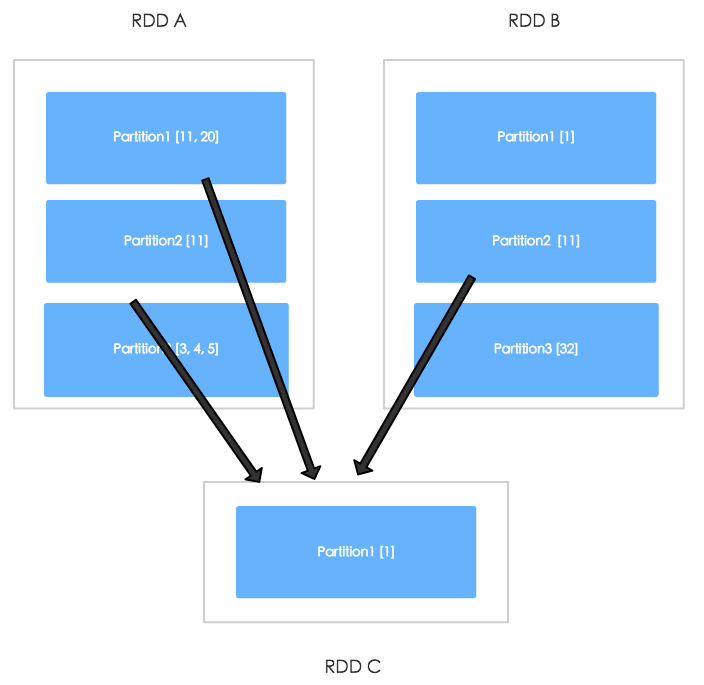
假设上图的RDDA, RDDB join的时候采用的是HashPartitioner(10),那么RDD C中的某个分区中都是key.hashCode % 10为1的数据,因此RDD C的Partition1需要从RDD A
的Partition1,Partition2,从RDD B的Partition 2中获取数据。
试想一下,如果两个RDD都按照同样的Partitioner预先对于数据进行了调整,那么在join的时候就只需要从固定个父分区中获取数据,因此就可以在join的时候避免了shuffle。 当然关于join操作,前期通过各种逻辑减少参与计算的数据也是很有必要的,更多关于join的优化可以参考高性能Spark这本书。
val reducedRDDA = rddA.reduceByKey(new HashPartitioner(10), func)
val partitionerOfRDDA =
reducedRDDA.partitioner.getOrElse(
new HashPartitioner(reducedRDDA.getNumPartitions)
)
val reduceRDDB = rddB.reduceByKey(partitionerOfRDDA, func)
val resultRDD = reducedRDDA join reduceRDDB
DataFrame SortMergeJoin
由于Spark SQL中很多操作的设计借鉴了关系型数据库的思想,所以我们先来简单了解一下数据库中SortMergeJoin算法的大致流程。
在数据库的情景下,一般来说,作为连表的键,在一个表中通过是外键,在另一个表中通常是主键。
FK ----- PK
1 1
1 3
3
5
# left relation, right relation, join predicate
SortMergeJoin(LR, RR, JP(LR, RR))
Sort LR by JoinKey # better check whether it has been sorted
Sort RR by JoinKey
X = LR Pointer
Y = RR Pointer
do
if (V(X) <= V(Y))
if Equal
Output(Row(X), Row(Y)) # with projection
else
X move forward
else
Y Move forward
while (X != null && Y != null)
首先对于两边的关系按照连表键进行升序排序,然后开始遍历两边的记录。想象有两个指针X, Y分别指向左右的记录。每次左右两边任意一边移动之后开始进行扫描行的比较,如果相等就加入最后的结果集中,另外哪边小就将哪边的指针向前移动,最后直到两边的记录都被遍历完,整个操作结束。
但是在DataFrame的join中,左右两边的键可能都会重复。如果按照上面的规则,下面的右边关系(RR)中第2次3所对应的行就无法被获取到了,具体解决方案可以参考 org.apache.spark.sql.execution.joins.SortMergeJoin中的doExecute()方法。
LR ----- RR
1 1
1 3
3 3
5
关于排序的操作,在RDD中也有相应的实现,也就是org.apache.spark.shuffle.sort.SortShuffleWriter,它是通过org.apache.spark.shuffle.ShuffleManager获取的,SparkEnv初始化的时候,默认配置的是SortShuffleManager。
val shortShuffleMgrNames = Map(
"hash" -> "org.apache.spark.shuffle.hash.HashShuffleManager",
"sort" -> "org.apache.spark.shuffle.sort.SortShuffleManager",
"tungsten-sort" -> "org.apache.spark.shuffle.sort.SortShuffleManager")
// 默认是SortShuffleManager
val shuffleMgrName = conf.get("spark.shuffle.manager", "sort")
所以,RDD在join的时候会按照join键排序,因此上面l1, l2无论怎么调整元素顺序,最终输出的结果还是一样的。
case class LR(key: Int, name: String)
case class RR(key: Int, age: Int)
val leftDataFrame = {
// scala.util.Random.shuffle((1 to 100000).toList)
sc.parallelize(
(1 to 1000000).toList.map { idx =>
LR(idx, idx.toString)
}).toDF
}
val rightDataFrame = {
// scala.util.Random.shuffle((1 to 100000).toList)
sc.parallelize(
(1 to 1000000).toList.map { idx =>
RR(idx, idx)
}).toDF
}
val resultDataFrame = leftDataFrame.join(rightDataFrame, "key")
通过resultDataFrame.explain得到如下输出,再结合上面的解释不难理解,为什么DataFrame的SortMergeJoin避免了shuffle。
# 执行计划输出
== Physical Plan ==
WholeStageCodegen
: +- Project [key#2,name#3,age#9]
: +- SortMergeJoin [key#2], [key#8], Inner, None
: :- INPUT
: +- INPUT
:- WholeStageCodegen
: : +- Sort [key#2 ASC], false, 0
: : +- INPUT
: +- Exchange hashpartitioning(key#2, 10), None
: +- Scan ExistingRDD[key#2,name#3]
+- WholeStageCodegen
: +- Sort [key#8 ASC], false, 0
: +- INPUT
+- Exchange hashpartitioning(key#8, 10), None
+- Scan ExistingRDD[key#8,age#9]