HDFS的高可用(high availability)主要指的是namenode的高可用,也就是要保证当active namenode挂掉的时候,standby namenode能够马上”升级”成active namenode确保集群正常运转,也就是所谓的故障切换(failover)。
一般可以分为两种手动切换(manual failover)和自动切换(automatic failover),前者一般是开发人员主动去进行一些维护时使用的,而后者则需要借助一些外部的工具来实现,在生产环境中一般是配置是自动切换。当然在自动切换的模式下,我们也可以运行相关的命令来触发切换。
关于高可用,我们需要考虑如下两个主要问题:
(1) 集群中的namenode能够被告知或者通过某种主动的方式知道当前的active namenode发生故障
(2) 当某个standby namenode成为active namenode时候,它需要恢复到之前active namenode挂掉时状态,主要就是fsimage和edit log
下面,我们以自动切换模式为例,来解释上面两个问题。
ZooKeeper quorum和ZKFailoverController(ZKFC)
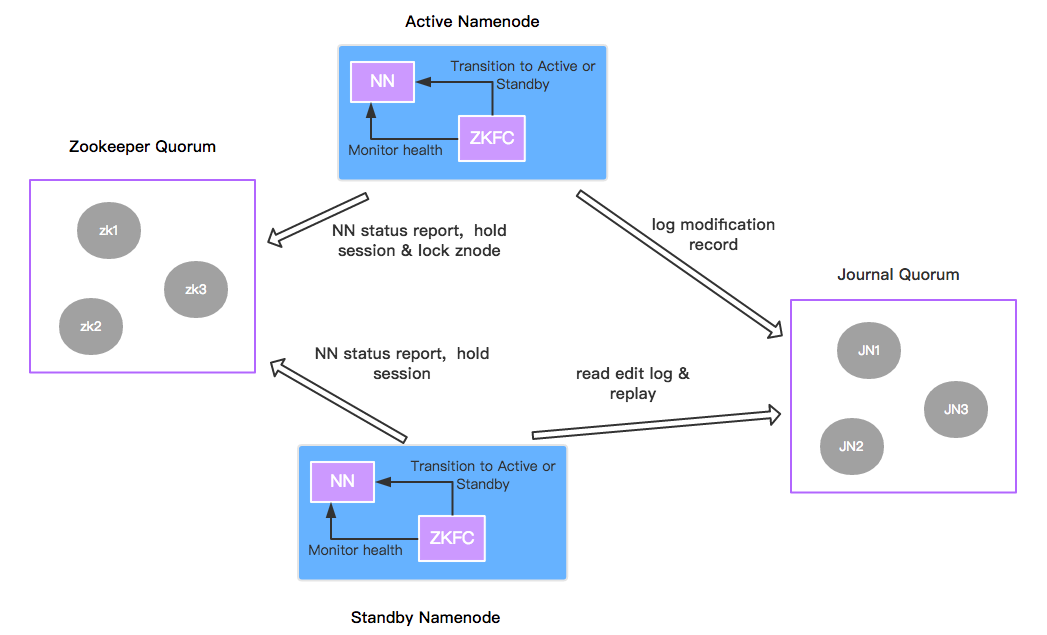
ZooKeeper quorum实际上就是Zookeeper集群,主要用来维护集群中的一些重要状态信息(比如说哪个namenode是active的),并且将这些信息的变动发送给客户端以及发送节点故障信息给客户端。
而ZKFailoverController实际上就是一个Zookeeper的客户端,因为Zookeeper是一个独立运行着的集群,想要获取HDFS namenode的相关信息,就必须在namenode节点上运行一个客户端程序来向Zookeeper Server汇报namenode的相关信息,包括如下几个方面:
(1) 故障监控 – 定期向Zookeeper汇报namenode的状态信息
(2) Zookeeper的session管理 – ZKFC建立连接的时候,会创建一个会话(之后所有的操作都是发生在该会话上面的)
(3) 基于Zookeeper的active namenode选举
Zookeeper会通过写一致性来选举出唯一的active namenode(通过锁的机制来完成)。 当多个ZKFC同时尝试创建一个临时的Znode(/hadoop-ha/${dfs.nameservice}/ActiveStandbyElectorLock),如果哪一个成功了,对应的namenode就变成了active。当连接断开或是其它情况导致会话被销毁时,ZKFC会主动删除该Znode。再次进入选举过程。
我们可以通过zk-shell(pip install zk-shell)来打印出Zookeeper中相应的节点。
zk-shell hostname:2181 --run-once "tree /hadoop-ha"
与HDFS相关的Znode:
│ ├── ${dfs.nameservice}
│ │ ├── ActiveBreadCrumb
│ │ ├── ActiveStandbyElectorLock
然后通过Zookeeper命令行就可以知道ActiveStandbyElectorLock中的数据,该Znode就包含了active namdenode的相关信息:
./zkCli.sh -server hostname:2181
[zk: hostname:2181(CONNECTED) 0] get /hadoop-ha/${dfs.nameservice}/ActiveStandbyElectorLock
cZxid = 0x570000c00d
ctime = Fri Feb 24 18:12:58 CST 2017
mZxid = 0x570000c00d
mtime = Fri Feb 24 18:12:58 CST 2017
pZxid = 0x570000c00d
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x15a21bcc2a30062
dataLength = 31
numChildren = 0
所以,HDFS中namenode的故障检测是依赖Zookeeper的,这解决了我们上面提到的第一个问题。
Quorum Journal Manager(QJM)
在Hadoop Namenode和DataNode中,我们提到的fsimage和edit log都是存在同一个节点的。如果节点发生故障,那么其它的namenode就无法获取最新的edit log。
为了保证高可用,HDFS中采用了Quorum Journal Manager,实际上就是journal node的集群。当active namenode将修改操作写入到半数以上的journal node中并且”反馈”已经成功了,该操作才算真正完成。一般部署三台的话,就需要两台以上确认成功写入。
与此同时,standby namenode也会定期读取edit logs进行fsimage的合并工作,和Hadoop Namenode和DataNode中提到的类似。通过这种机制,所有的stanby namenode都确保自己能够获取HDFS的最新状态。不仅如此,我们知道所有文件的block位置都是存储在namenode的内存中的,为了加速故障切换(failover),datanode会同时向active和standby namenode汇报位置信息。
所以,HDFS中的QJM解决了我们上面提到的第二个问题。
基本过程
ZKFC进程一直监控着namenode进程的状态,并且向Zookeeper汇报。当出现故障后,销毁之前建立的会话,Zookeeper删除相应的Znode。此时,其它的ZKFC监测到目前Zookeeper中没有master znode,并尝试创建master znode,一旦成功便告知namenode开始进行转换(standby –> active)。
至于具体配置,可以参考官网上使用QJM实现HDFS HA的Deployment部分。
另外,我们需要注意的是,Zookeeper并不是HDFS HA的必备组件,它的引入只是为了实现自动故障切换。HDFS HA的核心还是Quorum Journal Manager,毕竟确保集群正常运行,最重要的就是做好fsimage和edit log的容灾。
最后,几个重要知识点总结:
-
Quorum Journal Manager保证各个namenode之间共享edit logs但是只有active namenode能够写入并且以写入半数以上的journal node为成功依据,standby namenode可以定期读取edit logs然后进行重演,更新其fsimage。
-
Namenode的状态由ZKFC进行监控并且定期汇报给Zookeeper的,另外namenode从stanby到active的切换也是由它发起的。
参考
> Hadoop权威指南第4版 第三章Hadoop分布式文件系统
> ZooKeeper:分布式过程协同技术详解