NameNode和SecondaryNameNode
NameNode主要是管理文件系统树(filesystem tree)和所有文件目录以及文件的元数据的(metadata),它们以fsimage的形式存在磁盘中,当然运行的时候是在NameNode的内存中的并且会定期落盘。而edit logs则记录了每一次改动。Secondary NameNode的主要工作就是fsimage的合并以及在namnode发生故障进行时相关的恢复。
我们可以通过HdfsImageViewer来将fsimage转换成易读的格式(xml, txt)。 fsimage位于NameNode所在节点上的 ${hadoop.tmp.dir}/dfs/name/current文件夹下,关于具体的配置后文有提到。
hdfs oiv -i fsimage_xxx -o ~/Desktop/fsimage.xml -p XML
# fsimage.xml 片段
<inode>
<id>17173</id>
<type>DIRECTORY</type>
<name>sh</name>
<mtime>1485247276755</mtime>
<permission>allen:supergroup:rwxr-xr-x</permission>
<nsquota>-1</nsquota>
<dsquota>-1</dsquota>
</inode>
<inode>
<id>32064</id>
<type>FILE</type>
<name>part-00000</name>
<replication>3</replication>
<mtime>1487145513220</mtime>
<atime>1487145512798</atime>
<perferredBlockSize>134217728</perferredBlockSize>
<permission>allen:supergroup:rw-r--r--</permission>
<blocks>
<block>
<id>1073748647</id>
<genstamp>7824</genstamp>
<numBytes>32</numBytes>
</block>
</blocks>
</inode>
<INodeDirectorySection>
<directory>
<parent>16385</parent>
<inode>17173</inode>
....
</directory>
...
<INodeDirectorySection>
上面的xml片段让我们对于文件系统树和元数据有了更清晰的认识,前者描述的是HDFS中文件夹的层次结构,后者指的是文件夹以及文件的元数据(文件的有几个副本、修改时间、访问时间、访问权限、block大小以及该文件有多少块block构成等)。
Each fsimage file contains a serialized form of all the directory and file inodes in the filesystem. Each inode is an internal representation of a file or directory’s metadata and contains such information as the file’s replication level, modification and access times, access permissions, block size, and the blocks the file is made up of. For directories, the modification time, permissions, and quota metadata are stored.
NameNode文件结构
NameNode的相关文件都放在${dfs.namenode.name.dir}(在hdfs-site.xml中配置),默认地址file://${hadoop.tmp.dir}/dfs/name(hadoop.tmp.dir属性在core-site.xml中配置)。
一个运行的NameNode有如下的文件结构:
# 借助`tree`命令打印出如下结构
${dfs.namenode.name.dir}
├── current
│ ├── VERSION
│ ├── edits_0000000000000000001-0000000000000000002
│ ├── edits_0000000000000000003-0000000000000000038
│ ├── ...
│ ├── edits_0000000000000013701-0000000000000013702
│ ├── edits_inprogress_0000000000000013703
│ ├── fsimage_0000000000000013700
│ ├── fsimage_0000000000000013700.md5
│ ├── fsimage_0000000000000013702
│ ├── fsimage_0000000000000013702.md5
│ └── seen_txid
└── in_use.lock
文件镜像和编辑日志(filesystem images & edit logs)
(1) 文件镜像(filesystem images)和编辑日志(edit logs)
当文件系统发生写操作(创建或者是删除)时,该事务(transactions)会被记录到编辑日志中。每一个编辑文件(segment)记录了相关的transactionId,同时某一个时刻只能有一个edit文件被编辑,比如上面的edits_inprogress_0000000000000013703,只有当事务写入完成并且同步之后,才会告知客户端成功写入。
文件镜像就是事务发生时(0000000000000013700),文件系统元数据的记录检出点(checkpoint)</b>。 它并不是实时写入的,因为随着文件系统的增加,每一次写入都检出的话,开销是非常大的。 不过这种做法并没有损失健壮性,当NameNode发生故障重启时,这时候最近的一个fsimage就会被加载到内存并且重演它之后的编辑日志。实际上这也是每一次NameNode重启之后会做的事。
默认情况下,会保留最近的两个,由hdfs-site.xml中的dfs.namenode.num.checkpoints.retained属性控制。fsimage并没有记录每一个block在哪个节点上,这个信息由NameNode维护在内存中,每次DataNode加入集群的时候,都会向NameNode汇报这个信息并且定期汇报。
由于编辑日志会无限制的扩张,从而导致重演时间变长,在此这期间NameNode进入安全模式,只可读,显然这是不可接受的。不过Hadoop提供了Secondary NameNode(并不是真正意义上的NameNode)来定期checkpoint fsimage,基本流程如下:
- Secondary NameNode会定期发起checkpoint请求(由dfs.NameNode.checkpoint.period指定,默认1小时)。当NameNode接收到checkpoint请求后,会结合seen_txid前滚(roll forward)当前的in_progress编辑文件,形成edits_0000000000000013703-0000000000000013708
- 然后新开一个编辑文件edits_inprogress_0000000000000013709,之后的事务记录都写入那个文件
- Secondary NameNode发起http get请求获取最新的编辑文件(可能有多个)以及fsimage(上面的13702),在内存中完成日志重演(roll forward, edits from 13703 - 13708)形成新的fsimage
- 通过http put回传合并好的fsimage,不过此时是以临时的.ckpt文件存在的; 之后会重命名成正式的fsimage,然后NameNode会删除不需要的fsimage。
从上面流程中,我们可以明白为什么Secondary NameNode不应该与NameNode放在在同一台机器,因为它也需要存储fsimage以及edit logs,几乎相同的内存占用。
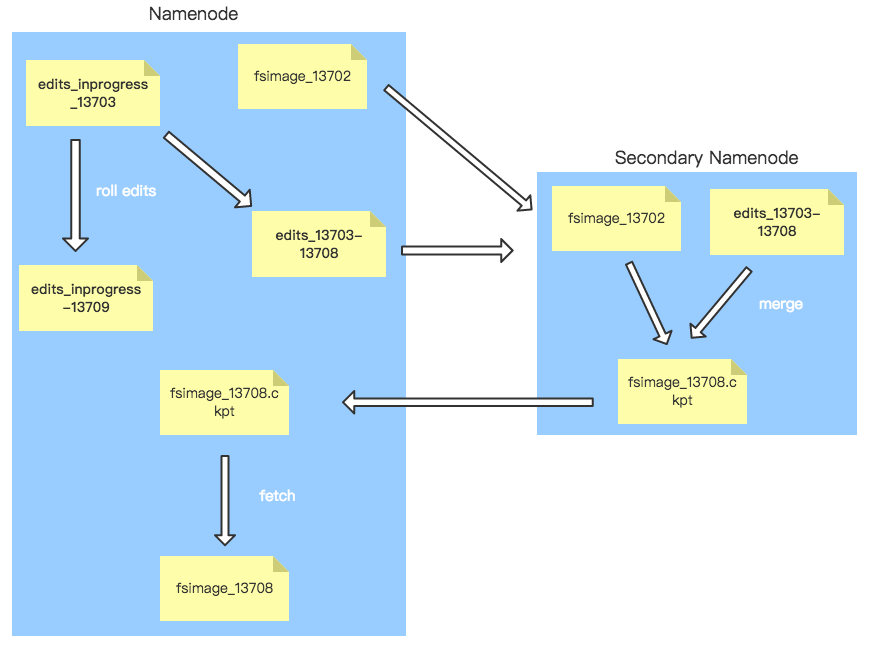
Secondary NameNode是定期checkpoint NameNode fsimage并且回传的,所以会存在一定的滞后(lag),如果在此期间NameNode发生故障,那么数据的丢失几乎是不可避免的。
在生产环境中,一般都是通过quoram journal manager结合Zookeeper来实现NameNode的高可用(High availability)的,具体可以参考Hadoop基础之HDFS的高可用。
(2) 版本信息(verison)
#Mon Dec 19 09:32:01 CST 2016
namespaceID=37525278
clusterID=xxxx
cTime=0
storageType=NAME_NODE
blockpoolID=BP-1613988217-192.168.111.226-1472103524578
layoutVersion=-63
- namespaceID: NameNode第一次格式化时候生成的文件系统的唯一命名空间(hadoop NameNode -format)
- clusterID: 集群Id(也就是hdfs-site.xml中配置的dfs.nameservices属性对应的值)
- blockpoolID: blockPool的唯一标识,包括了所有该NameNode管理的命名空间中的所有文件
DataNode
DataNodes主要根据NameNode或者是客户端的要求对于block进行各种操作,包括创建block的创建,删除以及接受NameNode的block replication指令,同时它们也会定期向NameNode反馈block的位置变化情况。当文件被存储的时候,它会被分成一个或者多个block并且被存放到不同的DataNode上面(由于replication level一般是3,所以通常会放到3个DataNode上面)。
DataNode文件结构
默认的位置: ${dfs.DataNode.data.dir}(在hdfs-site.xml中配置)
${dfs.DataNode.data.dir}/
├── current
│ ├── BP-1979375279-127.0.0.1-1479011039514 # 与NameNode中的blockpoolID相对应
│ │ ├── current
│ │ │ ├── VERSION
│ │ │ ├── dfsUsed
│ │ │ ├── finalized
│ │ │ │ └── subdir0
│ │ │ │ ├── subdir0
│ │ │ │ │ ├── blk_1073741825 # 存储着文件的原始字节
│ │ │ │ │ ├── blk_1073741825_1001.meta # 存储文件相关的原始数据
│ │ │ │ │ ├── blk_1073741826
│ │ │ │ │ ├── blk_1073741826_1002.meta
│ │ │ │ │ ├── blk_1073741827
│ │ │ │ │ ├── blk_1073741827_1003.meta
│ │ │ │ │ ├── blk_1073741828
.....
│ │ │ └── rbw
│ │ ├── scanner.cursor
│ │ └── tmp
│ └── VERSION
└── in_use.lock
参考
> Hadoop权威指南第4版 第二章分布式文件系统