之前在实现一个给executor使用的线程池时,直接将它broadcast了,这种用法被同事质疑了,他认为应该在executor上初始化线程池实现类。如果从broadcast方法的定义上来讲,这种质疑是合理的,因为它的初衷是将只读的变量广播到各个节点(driver or executor)上(Broadcast a read-only variable to the cluster),比如说通过数据库查询获取某种映射关系然后广播到各个节点上以减少重复查询。
加之在查看YARN Cluster Manager中的日志时,经常会看到TorrentBroadcast,甚是疑惑广播为什么会与Torrent产生关联,于是决定通过阅读源码来理清broadcast的实现。
broadcast的主要实现在org.apache.spark.broadcast.TorrentBroadcast中,之前一直以为broadcast的实现机制是在driver上将对象通过netty通讯传递到不同的节点上。但这种实现有一个问题,一旦broadcast变量比较大,并且节点比较多的时候,driver就容易成为瓶颈。
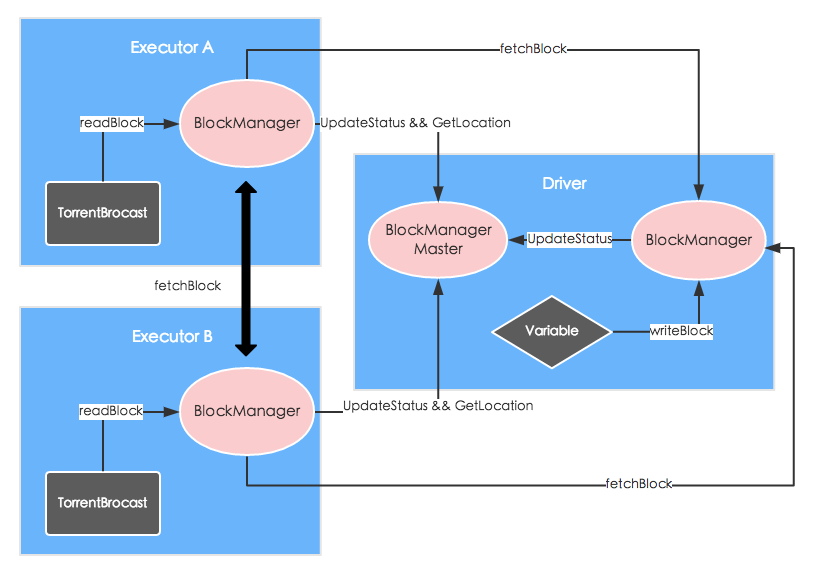
所以,Spark借鉴了BitTorrent的实现,大致流程如下图:
(1) TorrentBroadcast的初始化
在SparkEnv初始化的时候,BroadcastManager也完成初始化并且创建了新的TorrentBroadcastFactory,然后通过newBroadcast方法创建TorrentBroadcast。由于每一个broadcast变量需要先存储然后再获取,那么就需要使用某种标识,也就是我们在日志中看到的broadcast_0,broadcast_0_piece0。
val mapBC = sc.broadcast(Map("a" -> 1))
// broadcastManager在SparkEnv初始化的过程中被初始化
broadcastManager.newBroadcast[T](value, isLocal)
// uniqueBroadcastId -- nextBroadcastId.getAndIncrement()
broadcastFactory.newBroadcast[T](value_, isLocal, uniqueBroadcastId)
mapBC.getValue()
(2) 广播对象被切分成小块(chunk)并通过BlockManager进行存储
比如说刚开始在driver上进行广播操作:
首先会将对象直接以MEMORY_AND_DISK的storage level放到BlockManager中,方便之后的本地获取(不用反序列化,直接使用),唯一ID为broadcast_broadcastId的格式。
然后按照spark.broadcast.blockSize指定的大小(默认是4m)将对象切分形成Array[ByteBuffer],以MEMORY_AND_DISK_SER的storage level存储到BlockManager中,这样别的节点可以通过Netty通讯获取这些”碎片”,唯一ID为broadcast_broadcastId_field_Index的格式。
上面两种操作在日志中的反映就是:
INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 5.0 MB, free 5.0 MB)
INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 436.9 KB, free 5.4 MB)
实际上切分和存储的过程在TorrentBroadcast初始化的过程中就已经开始了。
new TorrentBroadcast {
// 获取拆分的block数目
private val numBlocks: Int = writeBlocks(obj)
// 触发变量拆分和block存储过程
writeBlocks(obj) {
if (!blockManager.putSingle(broadcastId, value, MEMORY_AND_DISK)) {
...
}
}
val blocks: Array[ByteBuffer] = TorrentBroadcast.blockifyObject(...)
blocks.zipWithIndex.foreach { case (block, i) =>
...
blockManager.putBytes(pieceId, bytes, MEMORY_AND_DISK_SER ...)
...
}
}
存储完成之后,会将相关的信息汇报给driver中的BlockManagerMasterEndpoint,它汇总集群中各个BlockManagerId中的BlockManager的情况, 也就是哪些executor上有哪些block。
关于上面的这种通讯模式在Spark其它地方也用到了,driver上的某个功能模块会有一个Endpoint和executor上对应功能模块的Endpoint进行沟通,一般会通过RPC。
(3) 通过TorrentBroadcast的getValue触发广播变量读取
比如说现在在executorA上需要获取上面的广播变量,则需要调用反序列化之后的TorrentBroadcast的getValue方法,进而触发readBlocks()方法。
它首先通过broadcast_broadcastId去本地的BlockManager中获取,因为之前有可能已经获取过了。
如果没有的话,获取之前拆分的block数numBlocks,按照指定规则拼接成pieceId(broadcast_broadcastId_field_Index);同样先从本地获取,然后从远端获取。 从远端获取,实际上就是给BlockManagerMaster发送获取Block位置的请求,但可能返回多个可供选择的位置,遍历进行获取,一旦成功则返回。
成功获取之后,就会存储在自己的BlockManager中,这样避免下一次重复获取。随着时间的推移,每一个Block可供获取的位置越来越多,直至最后成功的『下载』完整个广播变量,颇有些BitTorrent的感觉。
broadcast.getValue()
broadcast.readBroadcastBlock()
blockManager.getLocalValues(broadcastId)
Some(x) -> x
None -> readBlocks()
bm.getLocalBytes(pieceId) {
Some(block) -> block
None -> bm.getRemoteBytes(pieceId) -> put inn blockManager
}
val obj = TorrentBroadcast.unBlockifyObject()
obj