Spark中的stage划分是基于Shuffle Dependency的(Spark stages are created by breaking the RDD graph at shuffle boundaries)。
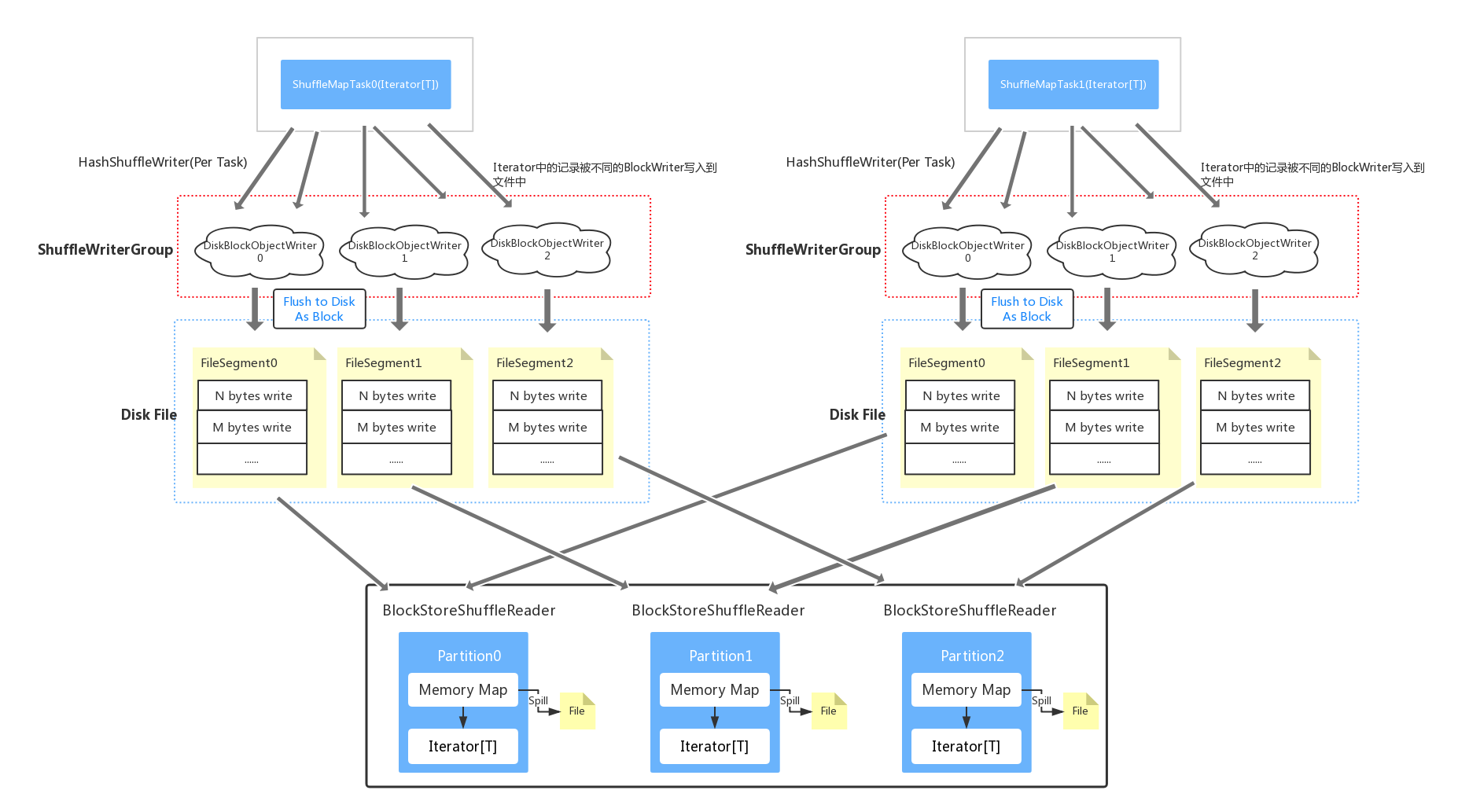
Shuffle总体分为两部分,基本的流程如下图:
- shuffle write -- 将ShuffleMapTask中的元素写到相应的文件中(当然也可以在内存中,文末会提到)
- shuffle read -- 从Shuffle block中去读取之前存储的文件
下面以一个简单的例子来梳理一下Shuffle的整个过程:
val pairList = List("a" -> 1, "a" -> 2, "b" -> 3)
// ParallelCollectionRDD =====> ShuffledRDD
// ShuffleMapStage =====> ResultStage
val finalRDD = sc.parallelize(pairList).reduceByKey(_ + _)
上面的操作会产生两个Stage:
(1) Stage 0 – ShuffleMapStage(对应parallelize操作),该Stage是在DAG执行流程中为shuffle产生数据的中间stage,它总是发生在每次shuffle操作(e.g. reduceByKey, join)之前并且可能会包含多个管道操作(e.g. map, filter)。但被执行之后,它们会存储map out文件(org.apache.spark.storage.FileSegment)以被后续的reduce任务读取。
(2) Stage 1 – ResultStage(对应reduceByKey操作),该Stage是一个Job的最后阶段。
INFO DAGScheduler: Final stage: ResultStage 1 (collect at SparkTest.scala:37)
INFO DAGScheduler: Parents of final stage: List(ShuffleMapStage 0)
INFO DAGScheduler: Missing parents: List(ShuffleMapStage 0)
Shuffle write(HashShuffle)
在Stage的提交过程中,如果有父Stage,会先提交父Stage以及它的相关任务; 如果RDD之间是ShuffleDependency(ParallelCollectionRDD, ShuffledRDD),则会产生ShuffleMapStage,进而产生ShuffleMapTask,而shuffle write正是发生在ShuffleMapTask的计算过程中的。 ShuffleMapTask的主要任务就是根据ShuffleDependency中定义的Partitioner将RDD中的分区数据重新分配到不同的文件中,以让shuffle read获取(A ShuffleMapTask divides the elements of an RDD into multiple buckets)。
dagScheduler.submitJob()
dagScheduler.handleJobSubmitted()
dagScheduler.submitWaitingStages()
dagScheduler.submitStage(stage)
dagScheduler.submitMissingTasks()
case stage: ShuffleMapStage => partitionsToCompute.map { id => new ShuffleMapTask(...) }
所以接下来,我们着重来研究一下ShuffleMapTask是如何实现shuffle write的,实际上就是 HashShuffleWriter的write操作做了哪些事。
(1) 生成HashShuffleWriter
// org.apache.spark.shuffle.FileShuffleBlockResolver
private[spark] class FileShuffleBlockResolver(conf: SparkConf) {
private val bufferSize = conf.getSizeAsKb("spark.shuffle.file.buffer", "32k").toInt * 1024
}
// org.apache.spark.scheduler.ShuffleMapTask
private val shuffle = shuffleBlockResolver.forMapTask(dep.shuffleId, mapId, numOutputSplits ...) {
blockManager.diskBlockManager.getFile(blockId)
blockManager.getDiskWriter( ... blockId ... )
}
shuffleMapTask.runTask()
manager = SparkEnv.get.shuffleManager
hashShuffleWriter = manager.getWriter(..partitionId..)
SparkContext初始化的时候会生成唯一的SparkEnv, 而它会生成各种ShuffleManager(包括HashShuffleManager, SortShuffleManager等)用于管理Shuffle的各个流程。当分区需要进行shuffle write的时候,HashShuffleManager会生成一个HashShuffleWriter,也就是说一个分区(一个Task)对应一个HashShuffleWriter。在HashShuffleWriter的初始化过程中还会生成一个FileShuffleBlockResolver(每一个Execuctor中只有一个), 它主要负责给shuffle task分配block(后面会详细解释)。
(2) HashShuffleWriter的写入过程
hashShuffleWriter.write
for (elem <- iter) {
val bucketId = dep.partitioner.getPartition(elem._1)
// Array[DiskBlockObjectWriter] in ShuffleWriterGroup
shuffle.writers(bucketId).write(elem._1, elem._2)
diskBlockObjectWriter.write(elem._1, elem._2)
diskBlockObjectWriter.write(elem._1, elem._2)
(objOut: SerializationStream).write(elem._1, elem._2)
}
hashShuffleWriter.stop(success = true).get
hashShuffleWriter.commitWritesAndBuildStatus()
val sizes: Array[Long] = shuffle.writers.map { writer: DiskBlockObjectWriter =>
writer.commitAndClose()
// writer.fileSegment() --> FileSegment
writer.fileSegment().length
}
HashShuffleWriter只是一个逻辑概念,因为真正的写入操作是ShuffleWriterGroup中的writers负责的。每一个ShuffleWriterGroup都会维护numOfReducer个DiskBlockObjectWriter, 也就是ShuffleDependency中的Partitioner中的分区数 – ShuffledRDD的分区数。然后ShuffleMapTask中的Iterator中的每一个元素都会通过key基于Partitioner计算出新的分区编号,也就是上面的bucketId,每一个bucket分配一个DiskBlockObjectWriter,然后将它们写入相应的SerializationStream中。
而DiskBlockObjectWriter则是由BlockManager(运行在每一个节点上 – Driver和Executor – 它提供本地或者远程,获取和存储block的接口无论是内存,磁盘还是off-heap)通过getDiskWriter生成的,并且关联了一个blockId, 它会被后续的shuffle read使用到,所以BlockManager提供了类似于getBlockData的方法。
注意在FileShuffleBlockResolver初始化的时候定义了一个spark.shuffle.file.buffer, 也就是SerializationStream中的buffer size,所以当流中字节超过指定的大小时,会被flush到文件中,而这个文件是和一个DiskBlockObjectWriter相对应的,DiskBlockObjectWriter会不断往该文件中追加字节,直到hashShuffleWriter.stop调用之后,所有写入完成形成一个最终的文件,也就是FileSegment(一个DiskBlockObjectWriter会对应一个FileSegment)。
关于这个追加过程在DiskBlockObjectWriter的源码中有一段解释:
/**
* ^ 表示文件中各种位置的游标
* xxxxxxxx|--------|--- |
* ^ ^ ^
* | | 最后一次追加后位置
* | 最近一次的更新位置
* 初始位置
*
* initialPosition: 开始往文件中写入时的位置
* reportedPosition: 最近一次写入后的位置
* finalPosition: 最后一次追加结束后位置,在closeAndCommit()调用后确定
* -----: 当前写入
* xxxxx: 已经写入文件的内容
*/
当ShuffleMapTask结束之后,还涉及到一个问题就是map out文件的路径汇报,也就是将相关的位置信息经由executor上面的MapOutputTrackerWorker 汇报给Driver上的MapOutputTracker, 这样其它executor需要获取相应的位置时就会向driver发送请求, 所以我们经常会在日志中看到这样的输出MapOutputTrackerMasterEndpoint: Asked to send map output locations for shuffle shuffleId to hostname:5505。
executor.run()
execBackend.statusUpdate(taskId, TaskState.FINISHED, serializedResult)
coarseGrainedExecutorBackend.statusUpdate(...)
driverRef ! StatusUpdate(executorId, taskId, state, data)
coarseGrainedScheduler$.backendDriverEndpoint
taskSchedulerImpl.statusUpdate(taskId, state, data.value)
taskResultGetter.enqueueSuccessfulTask(taskSet, tid, serializedData)
taskResultGetter.handleSuccessfulTask
taskSetManager.handleSuccessfulTask
dagScheduler.taskEnded
dagScheduler.handleTaskCompletion(completion)
mapOutputTracker.registerMapOutputs(...)
再次结合文章开头的shuffle write示意图,整个流程就相对清晰了。
Shuffle Read
在ShuffleMapStage运行完成之后,ResultStage开始运行,这里我们主要关注shuffle read是在何时被触发的。 所以,我们直接从Excecutor的任务执行开始切入。
(1) RDD分区计算的触发
// org.apache.spark.executor.CoarseGrainedExecutorBackend
executor.launchTask(...taskDesc.taskId ... taskDesc.serializedTask ..)
threadPool.execute(...TaskRunner...)
taskRunner.run()
task.run(...taskId...)
// ResultTask
task.runTask(context)
// func --> (TaskContext, Iterator[(String, Int)]) => Array[(String, Int)]
func(context, rdd.iterator(partition, context))
rdd.getOrCompute(split, context)
shuffledRDD.compute(split: Partition, context): Iterator[(K, C)]
execBackend.statusUpdate(taskId, TaskState.FINISHED, serializedResult)
从上面简化的代码来看,executor上面的任务启动之后会经过一系列调用触发Task的runTask方法,从而触发我们在action中的函数。 这里计算也许是从checkpoint处获取,也许是从cache中获取,也许是真正的计算。 本例中仅考虑真正的计算,那么我们就可以在ShuffledRDD的compute方法中看到ShuffleReader的相关逻辑。
(2) ShuffleReader的读取逻辑
shuffledRDD.compute()
shuffleManager.getReader(dep.shuffleHandle, split.index, split.index + 1, context)
BlockStoreShuffleReader(..startPartition, endPartition, mapOutputTracker...).read()
val blockFetcherItr = new ShuffleBlockFetcherIterator {
mapOutputTracker.getMapSizesByExecutorId(),
}
val wrappedStreams = blockFetcherItr.map { case (blockId, inputStream) =>
// (BlockId, InputStream) => InputStream
// blockFetcherItr.next() ==> (BlockId, InputStream)
// f(iter.next())
// InputStream
serializerManager.wrapForCompression(blockId, inputStream)
}
val recordIter = wrappedStreams.flatMap { wrappedStream =>
serializerInstance.deserializeStream(wrappedStream).asKeyValueIterator
}
serializerInstance.deserializeStream(wrappedStream).asKeyValueIterator
val aggregatedIter: Iterator[Product2[K, C]] = { aggregation process }
首先,ShuffleReader是由BlockStoreShuffleReader实现的;
当计算分区中的数据时,它需要获取上一个阶段map out的文件。它会根据shuffleId, 分区的index等信息去driver上的mapOutputTracker获取block的信息。同样的每一个分区会对应一个BlockStoreShuffleReader。
ShuffleBlockFetcherIterator初始化的时候,会进行将本地block获取和远程block获取进行拆分,本地获取交由本地blockManager负责;而远程block则通过发送FetchRequest来获取
。Spark限制了每一批次请求中请求字节的总大小(spark.reducer.maxSizeInFlight), 因此Block的请求是分批完成的,请求完成之后返回的ManagedBuffer通过相应的处理反序列化成了Iterator[(K, V)]。
接下来进入聚合阶段, 像上面的reduceByKey,在shuffle write的时候就已经在分区内部的进行一次聚合(mapSideCombine),此时只需要按照指定的函数,比如说上面的 value1 + value2汇总值即可。这个逻辑是由ExternalAppendOnlyMap实现的,在聚合Value的过程中,map的内存占用会越来越大。 因此,会涉及到是否spill到磁盘的逻辑,简单的理解就是当超过某个阈值之后(spark.shuffle.spill.initialMemoryThreshold),就会spill到磁盘。但实际过程中还会尝试申请更多内存,具体逻辑可参考org.apache.spark.util.collection.Spillable的maybeSpill方法。
我们有时会在Spark UI中的Tasks视图中看到shuffle spill(memory)和shuffle spill(disk)这两个指标 – 前者指的是发生Spill的时候,当前collection的内存占用,而后者则是实际spill到磁盘上的字节大小。
// org.apache.spark.util.collection.Spillable
protected def maybeSpill(collection: C, currentMemory: Long): Boolean = {
var shouldSpill = false
...
// Actually spill
if (shouldSpill) {
// ExternalAppendOnlyMap.spill => spill到磁盘的操作
spill(collection)
_memoryBytesSpilled += currentMemory
...
}
shouldSpill
}
总结
- ShuffleDependency产生ShuffleMapStage,ShuffleMapStage生成ShuffleMapTask
- Shuffle write发生在ShuffleMapTask的计算过程中,每一个ShuffleMapTask会对应一个ShuffleWriter,它会将分区中元素按照相应的规则写入不同的文件中,也就是我们通常看到的map out files或者是block files
- Shuffle read通过MapoutTracker获取相应的block file并借助各种Map对于数据进行汇总,这个过程涉及到将元素写入到磁盘的过程