在大数据开发领域,我们经常会碰到组件需要多节点部署并且为一主多从模式的,比如Hadoop NameNode分为active namenode,standby namenode; Kafka中多个Broker中会有一个选举成为Leader Controller。目的都是为了发生故障时,能够迅速恢复,也就是我们说的高可用,这两个组件都利用了Zookeeper进行主节点选举。
在Zookeeper高级应用中也提到了Leader Election,在此简单梳理一下官网的实现思路。
实现思路
假设/election/为选举节点的根目录,基本流程如下图所示:
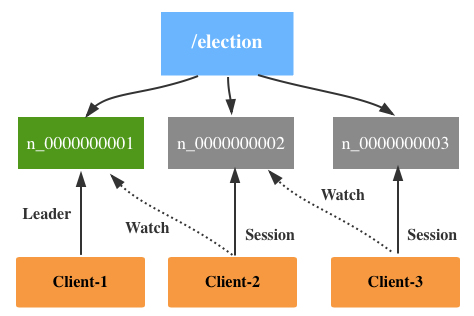
1.创建Znode
节点启动的时候,尝试在下面创建n_number的Znode,类型为EPHEMERAL_SEQUENTIAL,瞬时且后面跟10位依次递增的数字(10 digit sequence number)。
2.领导选举
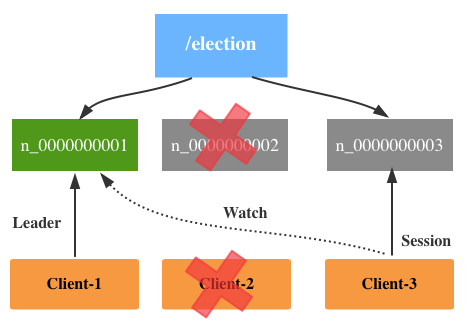
在创建的过程中,如果发现自己是/election/下面number最小的,则对应的Client成为新的Leader,上图中Client-1对应的Sequence number是最小的,所以成为Leader。
3.监控领导节点
在领导选举中比较关键的就是Znode Watch,如果让其它非Leader的Znode同时监控Leader Znode的变化的话,当Leader Znode因为某种原因挂掉的话,那么同一时间可能有很多Znode收到通知(notification),进而尝试成为新的Leader,也就是我们在Zookeeper中经常听到的羊群效应(Herd Effect)。
所以,Zookeeper采取的方式是,对于非Leader Znode只要监控比它小的一个Znode即可(the next znode down on the sequence of znodes),也就是上图所示的Client-2监控n_0000000001,Client-3监控n_0000000002。
当Leader Znode挂掉的时候,正常情况下,Client-2就会成为新的Leader。但假设Client-2在运行过程中挂掉了,这时候Client-3就会接收到通知,并且尝试去成为Leader。但由于Client-1还在,所以它所对应的Znode的Sequence Number不是最小的,所以无法成为新的Leader,与此同时它也会开始监控Client-1对应的Znode。