数据库综述系列主要是参考CMU15-721课程中提到的Database System Report,针对个人研究过的数据库(主要是OLAP方向)的核心架构进行梳理。ClickHouse目前已经是一个相当复杂OLAP数据库,所以主要会选择比较贴近实际开发的一些维度进行展开。另外由于笔者数据库水平有限,难免存在谬误,所以请带着审慎和批判的眼光阅读本文。
- 基础架构
- 存储的设计(数据结构设计、索引的设计以及利用等)
- 分布式表的写入流程剖析(包括不限于写入之后的数据同步)
- 分布式表的查询流程剖析(包括不限于查询时候的索引使用)
1. 基础架构
ClickHouse是一个使用C++开发的高性能,基于列存的分析型数据库。
1.1 MPP
MPP(Massively Parallel Processing,大规模并行处理)架构是将多个处理节点通过网络连接起来,每个节点是一台独立的机器,节点内的处理单元独占自己的资源,包括内存、硬盘等,也就是每个节点内的CPU不能访问另一个节点的内存,MPP架构服务器需要通过软件实现复杂的调度机制以及并行处理过程
1.2 Share Nothing
由采用MPP架构,各节点都有自己私有的CPU、内存、硬盘等,不存在共享资源,每个节点是一台SMP(Symmetric Multi Processing – 对称处理器)服务器,在每个节点内都有操作系统和管理数据库的实例副本,管理本节点的资源,节点间通过网络通信,能够处理的数据量更大,适合复杂的数据综合分析,对事务支持较差或者在实现事务方面会比较复杂,因为一次写入或者查询涉及到了分配到不同节点的数据。 这一点在当前2024年已经发生了比较大的变化,目前比较流行的OLAP系统,像StarRocks、Doris等,都已经开始转换到存算分离的架构。小红书也有过类似的分享,ClickHouse存算分离改造:小红书自研云原生数据仓库实践。
1.3 Column-oriented storage & Data compression
列式存储可以减少不必要的磁盘IO,由于同一列的数据性能类似,更可能存在重复,所以这又为数据压缩提供了基础,ClickHouse不仅提供了通用的压缩算法,还针对特定的数据类型采用了定制化的压缩算法。
1.4 Distributed Query Execution
这个主要是指在分布式表中,查询可以分散到不同的Shard上执行,达到Parallel Execution的目的,最终由查询发起节点合并中间结果。
The
Distributedtable requests remote servers to process a query just up to a stage where intermediate results from different servers can be merged.
1.5 Vectorized Query Execution
向量化执行,核心借助CPU的SIMD Capability,批量的操作数据,Single value —> Array,充分利用CPU的性能。 在OLAP蓬勃发展的当下,这个执行技术几乎成为了标配,但查询处理的另外一个技术: Runtime code generation也是一个很重要的优化手段,比如说Spark SQL的Whole-Stage Java Code Generation – fuses multiple physical operators (as a subtree of plans that support code generation) together into a single Java function。
1.6 Query Pipeline
这块也就是数据库的Query Processing Model,ClickHouse采用的是pipeline execution model,简单理解就是将SQL拆分成不同的部分,显示的控制执行流程,产生依赖的部分,就像管道的上下流一样,同一层级的算子可以并行执行。当然实际的运行流程比这个会更复杂,关于更多Query Pipeline的解释,可参考github What’s the difference between Clickhouse’s pipeline execution and Volcano model?。
1.7 Asynchronous Multi-Master Replication
这个地方主要是指分布式表的两个Replica之间,都可以作为Leader Replica接受数据写入,然后另外一个作为Follow Replica 从对方进行数据同步。
1.8 Attention to Low-Level Details
如果浏览过ClickHouse源码,会对于这点有更深的体会: 每个特殊场景,专向优化。我们知道在数据库实现group by的时候一般会基于group key进行哈希分桶,为了更高效的实现分组,ClickHouse针对不同分组key类型,实做了不同的定制化实现。
using AggregatedDataWithUInt8Key = FixedImplicitZeroHashMapWithCalculatedSize<UInt8, AggregateDataPtr>;
using AggregatedDataWithUInt16Key = FixedImplicitZeroHashMap<UInt16, AggregateDataPtr>;
using AggregatedDataWithUInt32Key = HashMap<UInt32, AggregateDataPtr, HashCRC32<UInt32>>;
using AggregatedDataWithUInt64Key = HashMap<UInt64, AggregateDataPtr, HashCRC32<UInt64>>;
using AggregatedDataWithShortStringKey = StringHashMap<AggregateDataPtr>;
using AggregatedDataWithStringKey = HashMapWithSavedHash<StringRef, AggregateDataPtr>;
using AggregatedDataWithKeys128 = HashMap<UInt128, AggregateDataPtr, UInt128HashCRC32>;
using AggregatedDataWithKeys256 = HashMap<DummyUInt256, AggregateDa
....
2. MergeTree存储结构
存储的设计很大程度决定了后续的查询执行、数据写入方式,ClickHouse采用了列存的结构,然后提供了各种表引擎,其中最常用的应该就是MergeTree系列引擎,所以如果能弄清楚磁盘中的文结构,那对于理解MergeTree的原理是非常有帮助的。不过MergeTree并不是LSM(log-segmented merge tree),因为它没有实现Memtable和Log,而是直接写入磁盘的。
具体而言,需要弄清楚如下问题:
- MergeTree Engine存储了哪些文件
- MergeTree Engine中表数据是存储的
- MergeTree Engine中索引是如何设计的
- MergeTree Engine中如何利用索引加快查询的
-- https://clickhouse.com/docs/en/optimize/sparse-primary-indexes 官网示例表
CREATE TABLE hits_UserID_URL
(
`UserID` UInt32,
`URL` String,
`EventTime` DateTime
)
ENGINE = MergeTree
PRIMARY KEY (UserID, URL)
ORDER BY (UserID, URL, EventTime)
SETTINGS index_granularity = 8192, index_granularity_bytes = 0;
2.1 表数据
2.1.1 每次写入形成一个data part
ClickHouse的每次成功写入会形成一个data part文件,实际上就是表分区数据的一部分; 显然每个分区的数据可能会包含很多data part,这也就是ClickHouse后台线程需要定时合并的原因,不然的话读取的时候需要扫描太多的data part。
2.2.2 data part会包含列元数据、数据以及索引信息
其中核心的文件如下表:
| 文件 | 说明 |
|---|---|
| columns.txt | 当前part对应的列元数据信息 |
| count.txt | 当前part的数据行数 |
| column_name.bin or data.bin | 压缩形式存储的列数据,基于wide 还是 compact决定是所有列公用一个还是一个列单独一个 |
| column_name.mrk or data.mrk | 记录压缩数据中block的offset 以及 解压缩之后granule的offset |
| minmax_column_name.idx | 跳数索引,一般会基于分区键默认创建跳数索引,比如说下面的minmax_EventDate.idx,如果基于其它列创建了,也会有对应的文件。 |
| primary.idx | 主键索引文件,记录了Granule的位置信息 |
| partition.dat | 记录了分区表达式生成了值,比如说针对partition by toYYYYMMDD(event_time),如果写入日期是2022-05-28,则会存储20220528 |
示例Part如下:
-rw-r----- 1 allen staff 258B Jun 5 16:33 checksums.txt
-rw-r----- 1 allen staff 10B Jun 5 16:33 default_compression_codec.txt
-rw-r----- 1 allen staff 117B Jun 5 16:33 columns.txt
-rw-r----- 1 allen staff 1B Jun 5 16:33 count.txt
-rw-r----- 1 allen staff 4B Jun 5 16:33 minmax_EventDate.idx
-rw-r----- 1 allen staff 4B Jun 5 16:33 partition.dat
-rw-r----- 1 allen staff 20B Jun 5 16:33 primary.idx
-rw-r----- 1 allen staff 208B Jun 5 16:33 data.bin
-rw-r----- 1 allen staff 176B Jun 5 16:33 data.mrk3
由于每一个data part包含了元数据信息,因此在进行一些DDL操作,比如说删除列的时候,需要扫描所有的文件夹进行操作。 对于大表来说,简直是灾难。
2.2.3 基于数据写入量的大小,会分成Wide vs Compact format
前者就是所有列会存放到一起,也就是只有data.bin & data.mrk3两个文件; 后者就是每一列会占用至少两个文件,一个column_name.bin & colunm_name.mrk。可以通过min_bytes_for_wide_part和min_rows_for_wide_part控制data part格式,当写入的时候内存中缩的数据量大小或者行数,任意一个小于这个阈值的时候,就会存储为Compact Format
Data part would be created in wide format if it’s uncompressed size in bytes or number of rows would exceed thresholds
min_bytes_for_wide_partandmin_rows_for_wide_part.
2.2.4 数据会基于Primary key进行排序(lexicographic ascending order)
像上面的hits_UserID_URL表,数据会基于(UserID, URL, EventTime)排序,也就是先按UserID,最后再按URL,最后再按照EventTime。
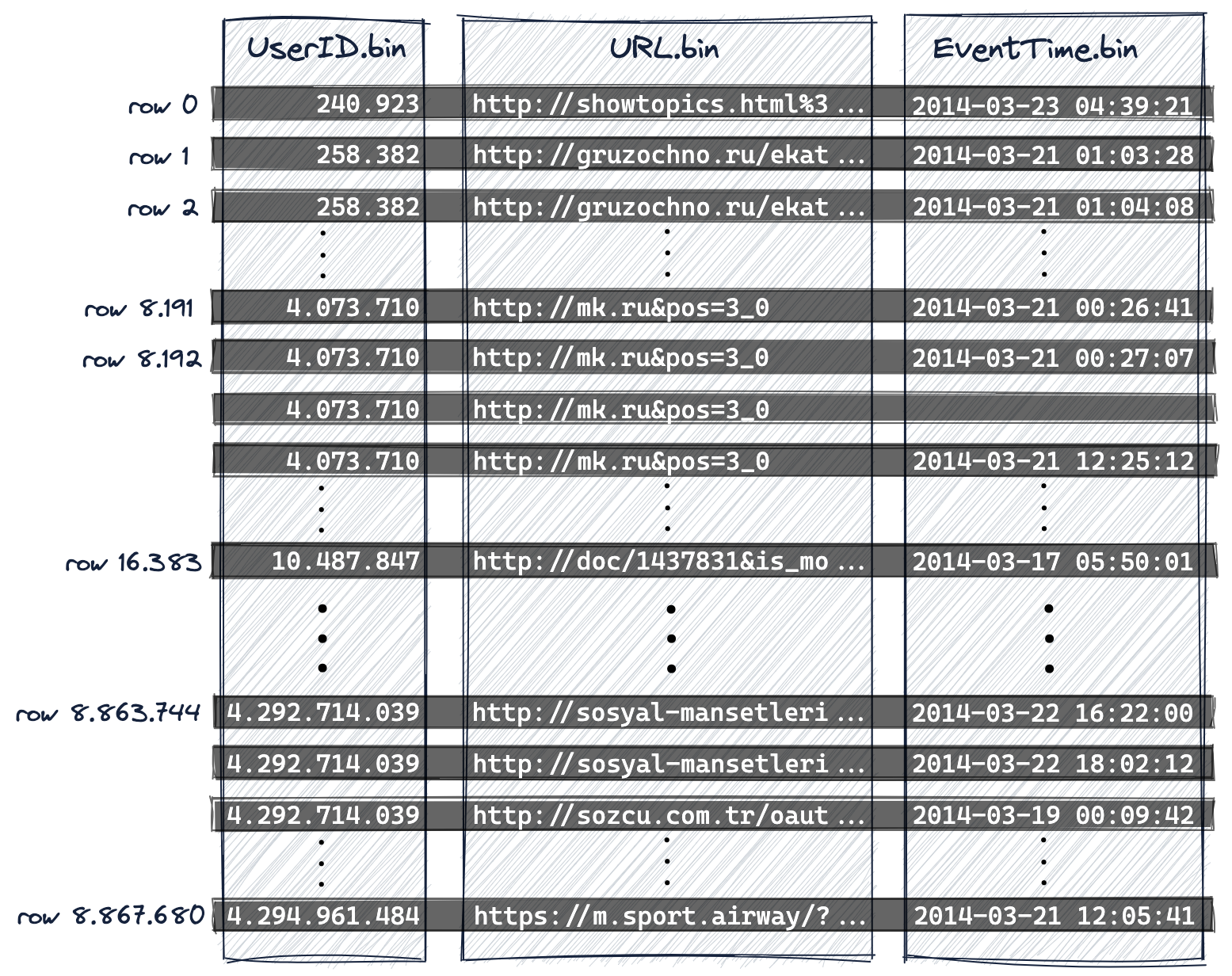
2.2 索引的设计-稀疏索引
上面我们提到了ClickHouse在磁盘上的数据存储结构,那么它是如何基于索引去定位到指定的part,然后从指定位置开始读取数据的呢?接下来我们以官网的示例表来讲解ClickHouse稀疏索引的设计与实现。
首先Clickhouse的一级索引(primary key)采用的是稀疏索引,是存储和性能上的一个折衷。另外ClickHouse索引会加载到内存中,如果针对每一个列值都创建的话,对于Clickhouse这种存储海量数据的MPP来说显然是不可以接受的。
The primary index file is completely loaded into the main memory. If the file is larger than the available free memory space then ClickHouse will raise an error.
2.2.1 为了数据的并行访问,写入的数据按照Granule组织
一个Granule对应index_granularity条记录,一般是8192。Granule是ClickHouse流式处理数据的最小单位(smallest indivisible data set),也就说ClickHouse读取数据是按照批次进行的。下图中前8192行(based on physical order on disk)属于Granule 0, 接下来的8192行属于Granule 1。
2.2.2 每一个Granule对应一个Index Entry
索引记录是基于Granule进行映射的,primary_index.mrk中的每一条记录(稀疏索引)记录的是,Granule内部各个主键列最小的值。 由于记录的并不是实际行对应的记录,所以会出现UserId-URL pair并不能定位实际的行。它表达的是给定UserID,对应的URL是指定Granule中最小的(alphabetically)。
UserID由于处在索引第一个位置,可以保证全局有序。就是所有的Granule中的值,都是大于240.923。
Index entries (index marks) are not based on specific rows from our table but on granules **E.g. for index entry ‘mark 0’ in the diagram above there is no row in our table where UserID is 240.923 and URL is “goal://metry=10000467796a411…”, instead, **there is a granule 0 for the table where within that granule the minimum UserID vale is 240.923 and the minimum URL value is “goal://metry=10000467796a411…” and
these two values are from separate rows.
下图中的橘色部分对应索引列在稀疏索引的中Entry。

2.2.3 查询时,基于主键索引(primary.idx)定位Granule
以下面的这个查询为例:
EXPLAIN indexes = 1
SELECT URL, count(URL) AS Count
FROM hits_UserID_URL
WHERE UserID = 749927693
GROUP BY URL
ORDER BY Count DESC
LIMIT 10;
由于UserID是组合主键索引的一部分,所以ClickHouse首先会基于primary.idx进行二分查找,定位相应的Mark记录。

主键索引文件中存储的是Mark index以及对应的Granule的起始行数据。
2.2.4 基于Mark记录号到column_name.mrk中,获取物理地址
上一步中定位到了Mark 176,这时候需要去UserId.mrk定位相应的物理地址
To achieve this, ClickHouse needs to know the physical location of granule 176。 In ClickHouse the physical locations of all granules for our table are stored in mark files. Similar to data files, there is one mark file per table column
Column.mrk中维护了两个offset:
- Block offset: 用于定位压缩列文件中的Block位置
- Granule offset: 用于定位解压之后Block中Granule的位置,一个Block中可能包含多个Granule
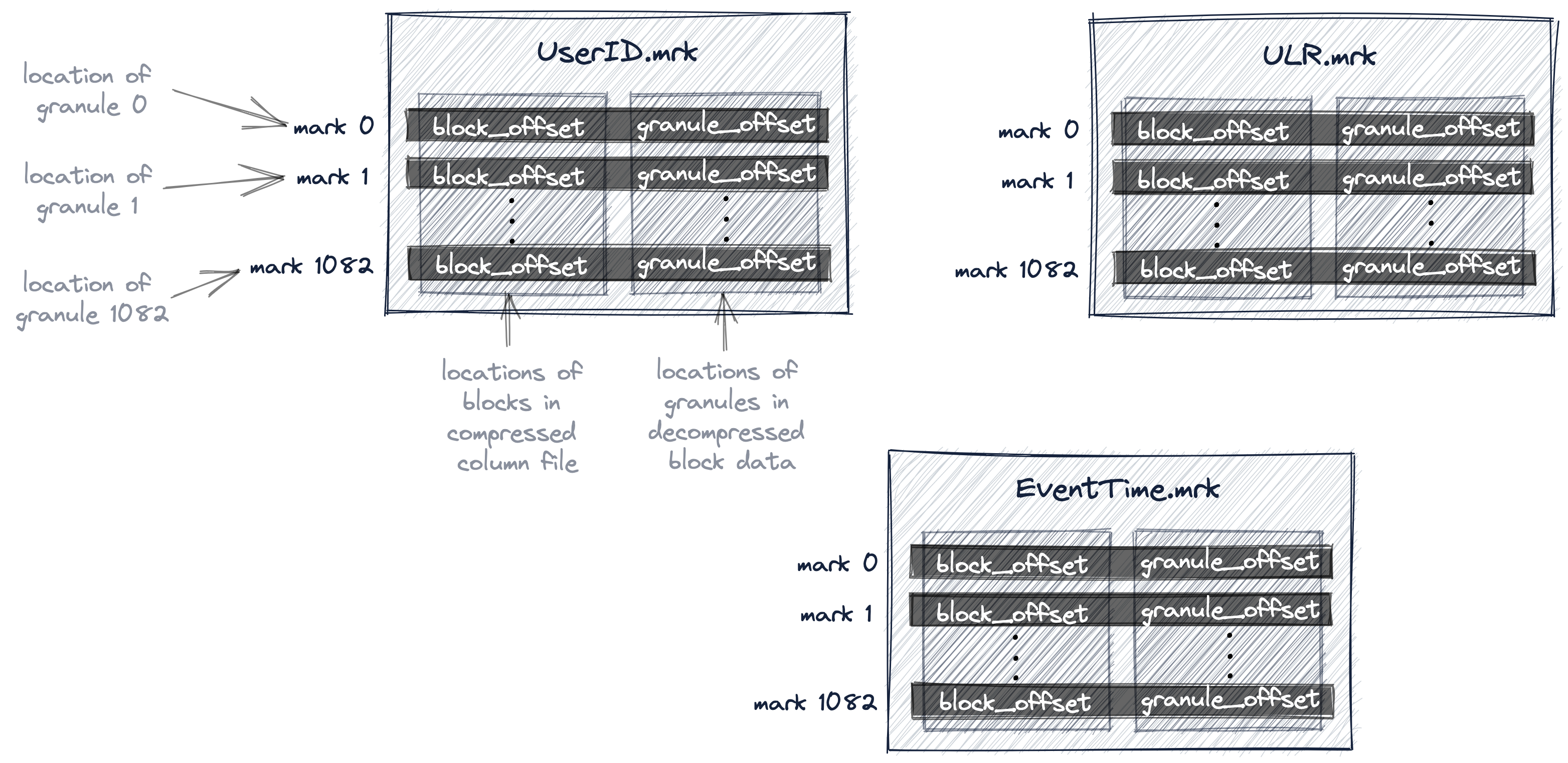
2.2.5 从column_name.mrk中获取相应的offsets到column_name.bin中加载数据
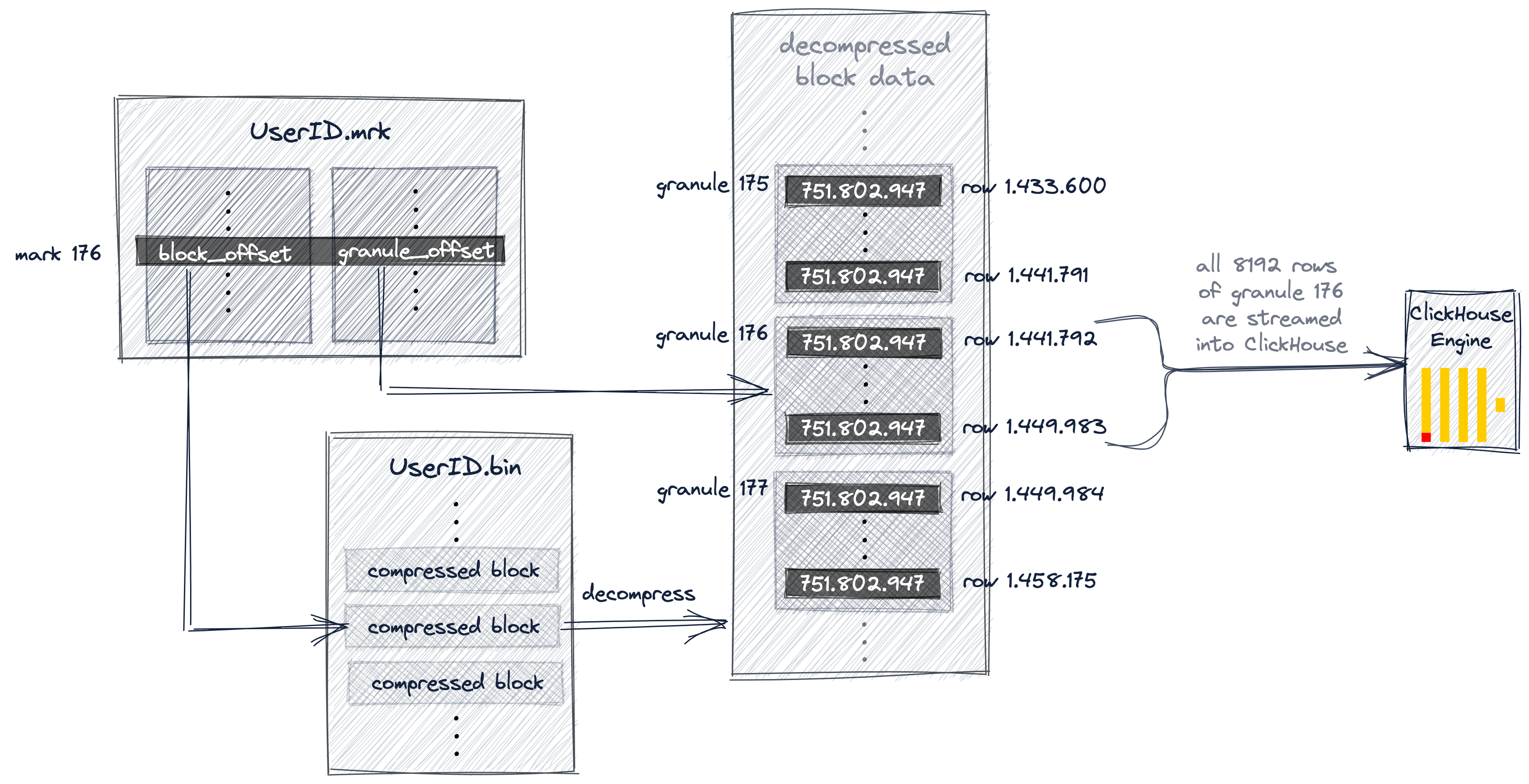
通过第一个offset,锁定UserID.bin中相应的compress block,然后可以去底层加载到内存,形成uncompressed block,接着使用granule offset去定位到指定的granule,然后定位到具体的行。由于查询数据可能涉及到了多个Granulue,所以这个时候可以Parallel Read。
Once the located file block is uncompressed into the main memory, the second offset from the mark file can be used to locate granule 176 within the uncompressed data.
有了MergeTree存储结构作为基础,下篇展开ClickHouse分布式读写的时候就会更容易理解。
3. 参考
> ClickHouse原理解析与应用
> ClickHouse What Makes ClickHouse so Fast?
> ClickHouse sparse primary index