关于Spring boot的自动装配原理我们已经在 Spring boot基础之自动装配 中详细讲过,由于基于Spring boot的Web开发基本都会使用到数据库,也就是会使用java.sql.DataSource,所以本篇主要基于阿里DruidDataSource梳理数据源的加载流程。
1. 基本配置
- Maven引入依赖
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.16</version>
</dependency>
- 依赖中会在spring.factories中配置对应的AutoConfiguration类
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
com.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceAutoConfigure
- application.yml中的配置,主要连接信息以及druid的相关信息
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://xxxx:3306/database?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&failOverReadOnly=false&serverTimezone=Asia/Shanghai&allowMultiQueries=true
database: xxx
username: xx
password: xxxx
2. DruidDataSourceAutoConfigure的初始化
@ConditionalOnClass(DruidDataSource.class)
// 在 DataSourceAutoConfiguration 之前先生效
@AutoConfigureBefore(DataSourceAutoConfiguration.class)
@EnableConfigurationProperties({DruidStatProperties.class, DataSourceProperties.class})
public class DruidDataSourceAutoConfigure {
@Bean
@ConditionalOnMissingBean
public DataSource dataSource() {
return new DruidDataSourceWrapper();
}
}
从上面的定义中,我们可以总结出如下几点:
- 需要项目中引入druid的相关依赖,这样才能使用DruidDataSource
- DruidDataSourceAutoConfigure 会在Spring boot官方自带的DataSourceAutoConfiguration之前先装配,目的就是要先初始化DataSource Bean。默认大多数会有ConditionalOnMissingBean来确保如果没有其他DataBean加载过,就会加载默认的
- 从@EnableConfigurationProperties说明支持 基于DataSource配置和Druid特定的统计相关的配置 暴露Bean(Enable support for @ConfigurationProperties annotated beans)
@ConfigurationProperties("spring.datasource.druid")
public class DruidStatProperties {
}
@ConfigurationProperties(prefix = "spring.datasource")
public class DataSourceProperties implements BeanClassLoaderAware, InitializingBean {
}
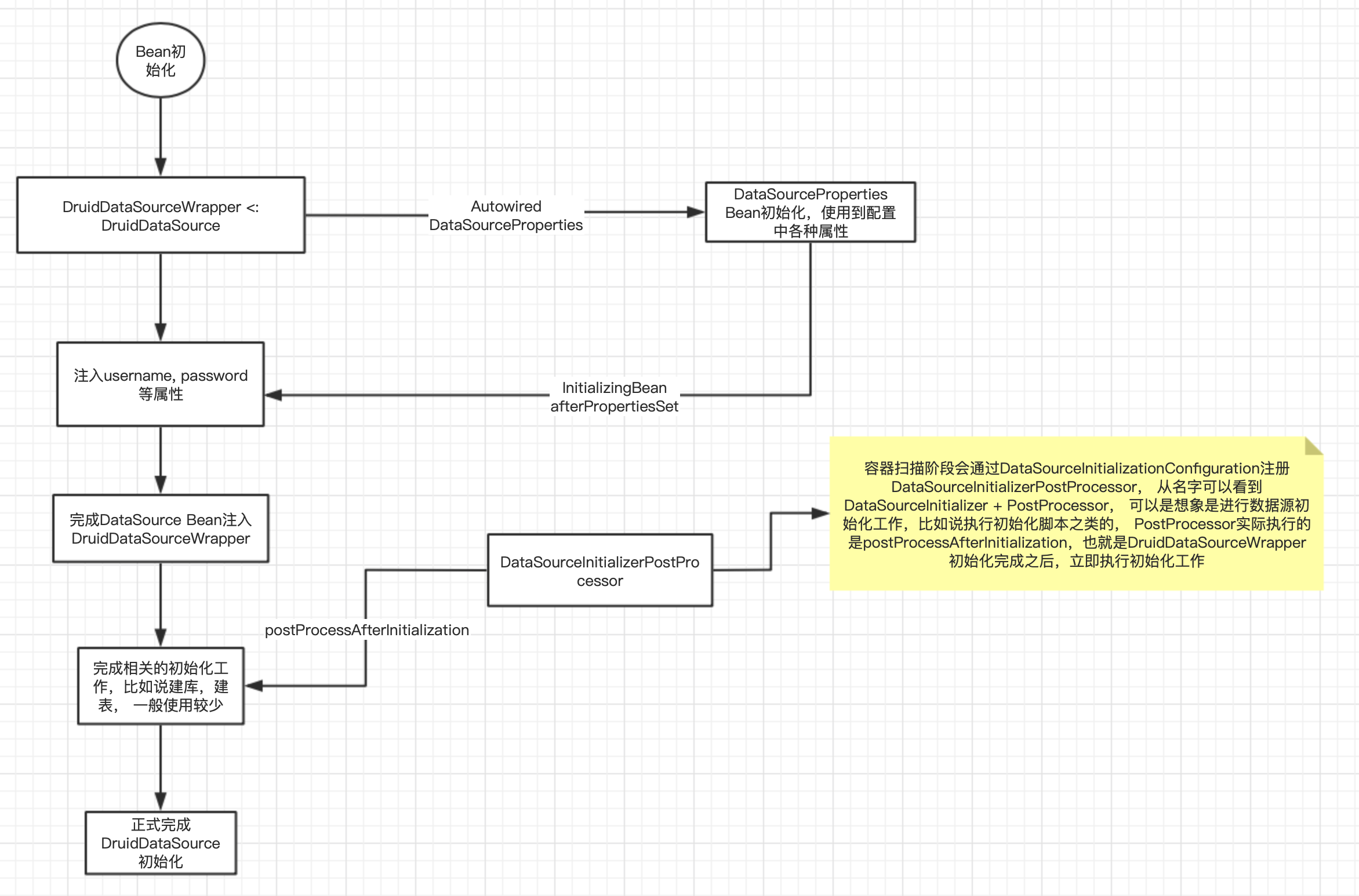
- 常规的配置都没有直接配置以spring.datasource.druid开头的属性,因为在DruidDataSourceWrapper已经做了对应的处理,通过InitializingBean的回调进行设置,
主要是要支持配置一些druid定制化的配置。
@ConfigurationProperties("spring.datasource.druid")
class DruidDataSourceWrapper extends DruidDataSource implements InitializingBean {
@Autowired
private DataSourceProperties basicProperties;
@Override
public void afterPropertiesSet() throws Exception {
// if not found prefix 'spring.datasource.druid' jdbc properties ,
// 'spring.datasource' prefix jdbc properties will be used.
}
}
大致流程图如下:
3. 执行Service方法的时候与DataSource的交互
@Service
public class ServiceImpl extends IService {
@Transactional
public Integer update() {
}
}
上面是Service实现类中,启用声明式事务(declarative transaction)的典型方法,底层是基于AOP实现的。 Service的update被调用的时候,触发切面,拦截开启事务,然后从DruidDataSource中获取连接,大致的调用栈如下。
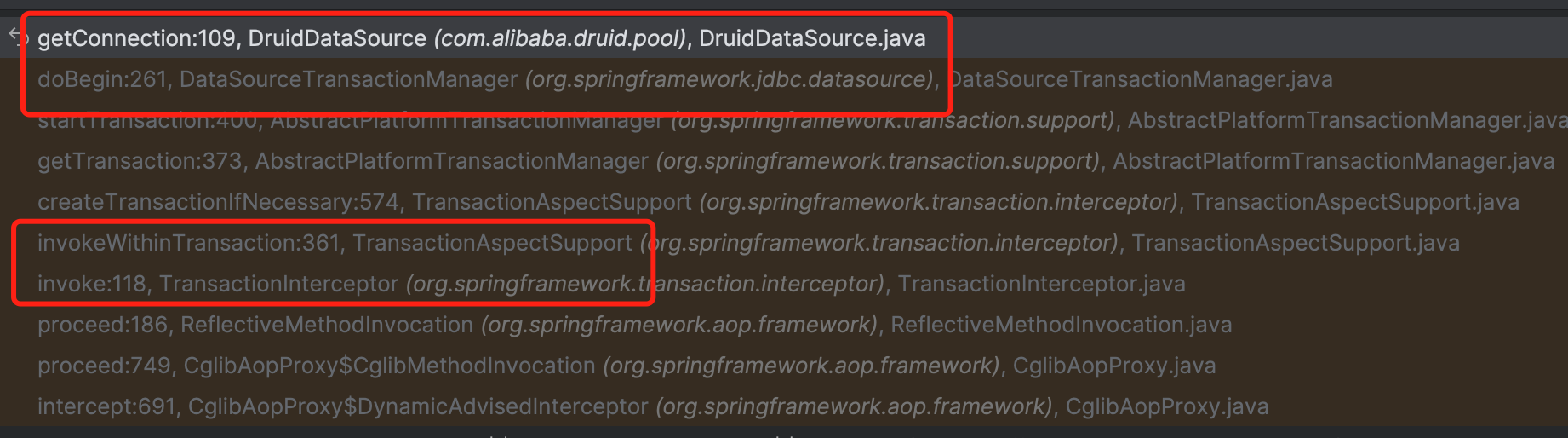
3.1 TransactionManager Bean注册
不用想肯定又是Spring boot AutoConfiguration那一套,一般来说Spring boot项目都会注册DataSourceTransactionManager, 而它的核心又是底层数据源DataSource,也就是我们上面提到的DruidDataSource。
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass({ JdbcTemplate.class, PlatformTransactionManager.class })
@AutoConfigureOrder(Ordered.LOWEST_PRECEDENCE)
@EnableConfigurationProperties(DataSourceProperties.class)
public class DataSourceTransactionManagerAutoConfiguration {
@Configuration(proxyBeanMethods = false)
@ConditionalOnSingleCandidate(DataSource.class)
static class DataSourceTransactionManagerConfiguration {
@Bean
@ConditionalOnMissingBean(PlatformTransactionManager.class)
DataSourceTransactionManager transactionManager(DataSource dataSource,
ObjectProvider<TransactionManagerCustomizers> transactionManagerCustomizers) {
DataSourceTransactionManager transactionManager = new DataSourceTransactionManager(dataSource);
...
}
}
}
3.2 真正调用的时候触发DataSourceTransactionManager获取连接的方法
DataSourceTransactionManager底层管理的是DataSource,获取连接实际是DataSource处理的,所以最终走到了DruiDataSource的getConnection方法。
4. DruidDataSource对于连接的抽象和封装
本质上DruidDataSource只是一个连接池,我们可以使用它连接MySQL、PostgresSQL、ClickHouse,所以会涉及到底层数据库JDBC连接的抽象和封装。
- 基于SPI加载不同的DriverManager,底层由不同数据库Driver(
com.mysql.jdbc.Driver,ClickHouseDriver)支持 - Connect url 决定使用哪种Driver
-
Driver进行连接的时候,返回的Connection,是实现了它的各种数据库特定Connetion,
ClickHouseConnectionMySQLConnection - 获取对应数据库连接之后,各种方法也可以进一步定制返回不同的Preparement之类的
那么DriudDataSource中的连接是如何基于原生的Connection进行包装的,以ClickHouseConnection为例。 一句话总结: 本质上DruidPooledConnection将物理连接(和数据库真实连接,一般为Connection), 抽象为 PhysicalConnectionInfo。
public static class PhysicalConnectionInfo {
private Connection connection;
private long connectStartNanos;
private long connectedNanos;
private long initedNanos;
private long validatedNanos;
private Map<String, Object> vairiables;
private Map<String, Object> globalVairiables;
}
class PhysicalConnectionInfo {
private:
Connection connection;
long connectStartNanos;
long connectedNanos;
long initedNanos;
long validatedNanos;
std::unordered_map<std::string, std::string> vairiables;
std::unordered_map<std::string, std::string> globalVairiables;
};
然后 提供一些额外的连接管理功能:
- 空闲连接自动关闭
- 连接失败自动重连
那么DruidDataSource是如何重连以及需要配置哪些参数呢,总结起来就是:
- 守护线程定时监控当前连接池状况,需要时候创建,创建失败的时候基于指定规则重连
CreateConnectionTask - 内部是一个基于ReentrantLock的生产者-消费者模式
CreateConnectionTask相当于生产者,GetConnection相当于消费者,两者通过ReentrantLock进行Synshronization
public class CreateConnectionTask implements Runnable {
//! 创建连接的时候 基于 connectionErrorRetryAttempts && timeBetweenConnectErrorMillis && breakAfterAcquireFailure 进行重试
try {
physicalConnection = createPhysicalConnection();
} catch (SQLException e) {
}
}