Spark在实际开发中一般使用YARN或Mesos作为集群管理器,它们一般有两个组件: Master服务(YARN ResourceManager, Mesos Master), 它们决定在哪些节点的哪些Executor上执行任务; Slave服务(YARN Nodemanager,Mesos Slave),它们上面启动了Executor。Master服务也会监控Slave的状态以及资源消耗。
Spark在YARN上的部署
Spark在YARN上一般有两种部署模式,一种是Client模式,一种是Master模式。它们之间一个显著的区别就是Driver Program运行的位置。前者是在启动程序的机器上运行的,而后者是Hadoop ResoureManager选择集群中的一个节点,启动ApplicationMaster进程,然后新开一个线程运行Driver Program,这一点在Yarn的日志中很容易发现。
INFO ApplicationMaster: Starting the user application in a separate Thread
对于Master模式的运行流程,大致如下:
(1) ApplicationMaster启动之后,会向ResourceManager注册,告知ResourceManager自己的一些基本信息,比如Hostname,Driver RPCEndRef之类。注册完成之后会生成一个org.apache.spark.deploy.yarn.YARNAllocator。
ApplicationMaster.main
master = new ApplicationMaster(amArgs, new YarnRMClient)
ApplicationMaster.run
ApplicationMaster.runDriver()
ApplicationMaster.registerAM()
YarnRMClient.register
(2) 然后YarnAllocator开始根据读取的SparkConf(各种资源的配置,如num-executors, driver-memory等)向ResourceManager申请资源
INFO YarnAllocator: Will request 40 executor containers, each with 1 cores and 2984 MB memory including 384 MB overhead
INFO YarnAllocator: Container request (host: Any, capability: <memory:2984, vCores:1>)
INFO YarnAllocator: Container request (host: Any, capability: <memory:2984, vCores:1>)
...
(3) 资源申请完成之后,通过ContainerManagementProtocol(ApplicationMaster与NodeManager之间的通讯协议),开始在NodeManager上启动容器以及Executor
ApplicationMaster.registerAM()
allocator.allocateResources()
YarnAllocator.allocateResources()
// Handle containers granted by the RM by launching executors on them.
YarnAllocator.handleAllocatedContainers()
YarnAllocator.runAllocatedContainers()
INFO YarnAllocator: Launching container container_e65_1478591460077_1290_01_000002 for on host server191
INFO YarnAllocator: Launching ExecutorRunnable. driverUrl: spark://CoarseGrainedScheduler@192.168.111.195:35611, executorHostname: server191
(4) 之后Driver Program会将Job划分为不同的Stage和Task,然后向ApplicationMaster发出资源请求,ApplicationMaster会与Resource Manager进行沟通以获取不同的资源组合(Container),然后将任务分发到不同的Container上去执行
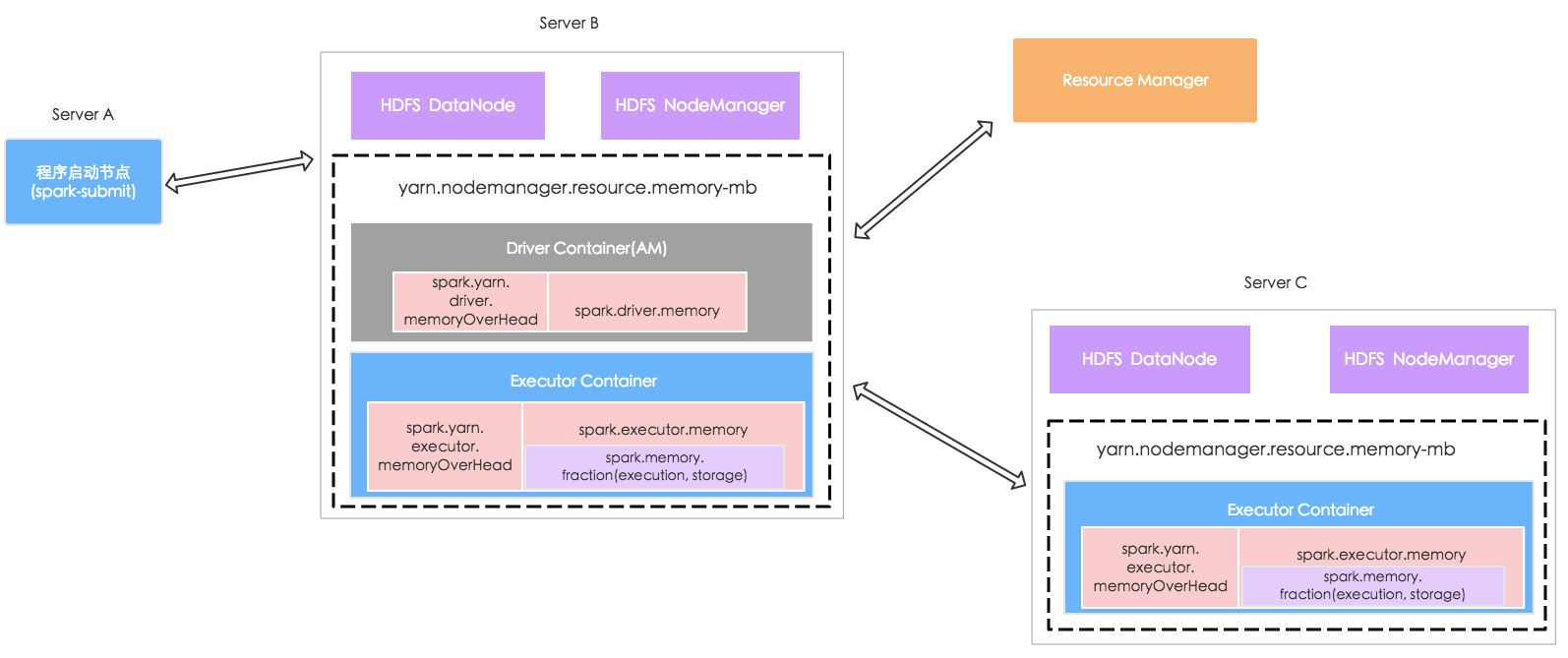
YARN Master模式的资源分配
在YARN资源管理中,一个Container(YARN对于资源的一种抽象,包括CPU和内存)对应一个Executor,实际上就是一个JVM实例,可以同时执行多个Task(通过executor-cores指定)。一个节点可以根据资源情况启动多个Container。Container一般分为Driver Container和Executor Container(官方并没有这种划分,这里只是为了理解方便)。 这个Driver Container实际上就是运行ApplicationMaster的。
在计算一个节点(Hadoop DataNode)可分配给Container的内存时,首先要剔除如下几部分: Hadoop DataNode守卫进程(1000MB),Hadoop NodeManager守卫进程(1000MB),节点本身运行(一般会留出1G),剩下的物理内存才是真正可以分配给Container的,一般会通过yarn-site.xml中的yarn.nodemanager.resource.memory-mb属性进行设置,它指定了节点上所有的Container可以使用的总内存。
对于Executor,ExecutorMemoryRequired = ExecutorMemory + ExecutorMemoryOverhead 前者我们一般通过executor-memory参数指定,后者的计算公式如下:
// org.apache.spark.deploy.yarn.YarnAllocator
// executor-memory -- 2g
protected val executorMemory = sparkConf.get(EXECUTOR_MEMORY).toInt
protected val memoryOverhead: Int = sparkConf.get(EXECUTOR_MEMORY_OVERHEAD).getOrElse(
math.max((MEMORY_OVERHEAD_FACTOR * executorMemory).toInt, MEMORY_OVERHEAD_MIN)).toInt
对于MemoryOverhead,首先会读取我们设置的,如果没有显示设置。则会取ExecutorMemory * 0.1与384m之间的最大值。
但是ExecutorMemoryRequired计算出来的值并不是最终Container申请的内存大小,还有一个因素需要考虑: yarn.scheduler.minimum-allocation-mb, 该属性可以理解为YARN内存分配的最小单位,默认是1024m。也就是说最终Container申请的内存一定是该属性的整数倍,如果说ExecutorMemoryRequired计算出来为2984m, 那么实际申请的就是3G。
关于ExecutorMemory部分,我们主要从两个方面考虑: Execution内存和用于存储的内存(cache)。 从1.6版本起,在SparkEnv初始化的时候,提供了两种MemoryManager:
// org.apache.spark.SparkEnv
val useLegacyMemoryManager = conf.getBoolean("spark.memory.useLegacyMode", false)
val memoryManager: MemoryManager =
if (useLegacyMemoryManager) {
new StaticMemoryManager(conf, numUsableCores)
} else {
UnifiedMemoryManager(conf, numUsableCores)
}
默认的情况下使用org.apache.spark.memory.UnifiedMemoryManager(A MemoryManager that enforces a soft boundary between execution and storage such that either side can borrow memory from the other.),也就是上面两种类型的内存使用并没有严格界限,可以互相占用。这也是1.6版本在内存管理方面的一个优化。
相反如果我们选择了LegacyMode,则会使用org.apache.spark.memory.StaticMemoryManager(A MemoryManager that statically partitions the heap space into disjoint regions.),也就是spark.shuffle.memoryFraction和 spark.storage.memoryFraction指定的内存区域会被严格区分,不能互相占用。
而对于Driver Memory,计算逻辑大致相同,只不过是通过ApplicationMasterOverhead来表达的:
// org.apache.spark.deploy.yarn.Client
private val amMemoryOverhead = {
val amMemoryOverheadEntry = if (isClusterMode) DRIVER_MEMORY_OVERHEAD else AM_MEMORY_OVERHEAD
sparkConf.get(amMemoryOverheadEntry).getOrElse(
math.max((MEMORY_OVERHEAD_FACTOR * amMemory).toLong, MEMORY_OVERHEAD_MIN)).toInt
}
接下来通过实际的运行来验证上面的观点,测试环境:
# yarn.nodemanager.resource.memory-mb ==> 13G
server191 server192 server193 server194 server195 均为4核 16G内存
# yarn.nodemanager.resource.memory-mb ==> 101G
server106 32核 128G内存
运行参数:
num_executors="40"
executor_cores="1"
driver_memory="3g"
executor_memory="2600m"
nohup spark-submit --class "xxxx" \
--master yarn --deploy-mode cluster \
--num-executors ${num_executors} --executor-cores ${executor_cores} \
--driver-memory ${driver_memory} --executor-memory ${executor_memory}
...
预计内存占用:
ExecutorMemoryRequired = 2600m + 1024m = 3624m ===> Container 4G
Driver = 3 * 1024m + 384m = 3456m ====> Driver Container 4G
根据日志了解到,ApplicationMaster启动在server193上面(Remoting started; listening on addresses :[akka.tcp://sparkDriverActorSystem@server193:40506]),所以server193上面应该会启动3个Container,各申请了4G内存(1个给Driver,另外2个给Executor),server191,192,194,195分别启动3个,这样已经启动14个ExecutorContainer。剩下的26个ExecutorContainer,如果server106上有足够的内存应该能全部启动起来(虽然设置的是101G,但是实际上可能并没有那么多可用的物理内存)。
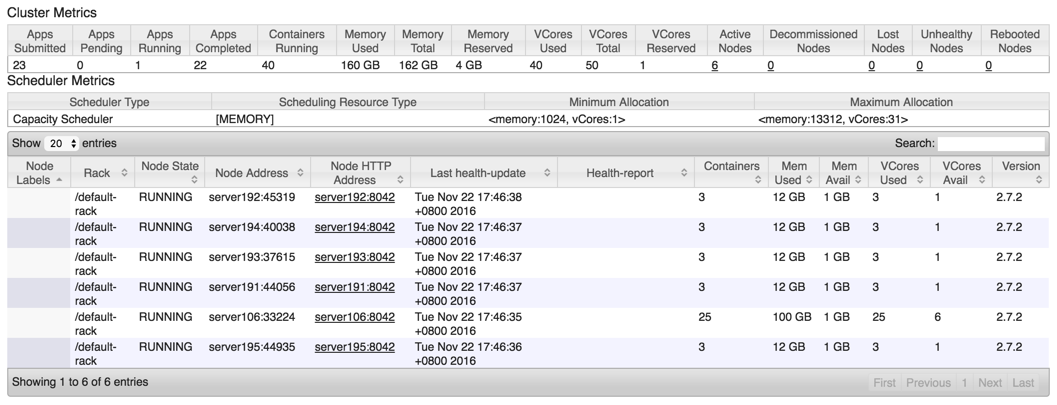
从Cluster指标上来看基本满足,本来server106上面应该是26个Container,但实际上只启动了25个,因为剩下的1G内存不足以再分配一个Container了。
后来尝试了修改了一下参数,减小Executor数(这样可以减小数据Shuffle的时候带来的网络传输),增大核数同时增大对应的Executor内存。
num_executors="25"
executor_cores="2"
driver_memory="3g"
executor_memory="5200m"
在这种情况,相同的环境下执行速度也有所提升。同时也尝试过另外一种配置,那就是将节点上的核数全部用满,这种情况下执行的速度明显下降不少,因为OS本身运行需要一定的CPU和内存,所以一定不要用尽节点上的CPU核数。
另外需要注意的是,默认情况下进入
http://hostname:8042/node/allContainers下的页面查看节点信息时:
TotalMemoryNeeded 6144
TotalVCoresNeeded 1
TotalVCoresNeeded会显示成1,即使设置成了多个,这个其实并不是计算的问题,而是Hadoop配置的问题。
参考
> Hadoop权威指南 第四版 第十章搭建Hadoop集群之YARN和MapReduce的内存设置