Spark Streaming的核心是DStream或Discretized Stream(离散流),代表着连续的数据流。 然后按照指定的间隔(duration)对数据进行切分并进行相应的计算,主要用于实时场景。DStream在每一个切分的时间片段对应的就是一个RDD,本质上DStream就是连续的RDD(a sequence of RDDS)。它依赖的数据源是多种多样的,比如说Kafka, Flume; 当然输出数据的存储介质也是多种多样的,比如说HDFS,Databases。
它主要有以下几个重要的组件:
- StreamingContext DStream执行的上下文,是基于SparkContext。
-
DStream Spark Streaming中对于流式数据的一种抽象,同RDD一样也有几个重要的部分,如果对于RDD比较熟悉的话,这几个概念应该不难理解。
- 一系列依赖的DStream(
List[DStream[_]]) - 生成RDD的时间间隔(
interval),实际上就是RDD的计算时间间隔 - 生成RDD之后的计算函数(
function)
- 一系列依赖的DStream(
- JobScheduler,负责DStream中Job的调度以及使用底层的线程池执行
- JobGenerator,接受JobScheduler的委托,生成DStream每个批次的任务
- DStreamGraph,维护每个批次的输入DStream和输出DStream,会与JobGenerator结合生成当前批次的Job
基本流程
下面我们以Kafka为数据源,构建DirectKafkaInputDStream(工作中主要是使用的是Direct方式),并进行简单操作。借此来解释一次简单的操作中,上述各个组件是如何协作的。
val conf = new SparkConf().setAppName("Kafka Direct Stream")
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc, Seconds(5))
// Kafka Producer向话题nums发送随机英文字母A - Z
val kafkaParams = Map("metadata.broker.list" -> "localhost:9092")
val kafkaDirectStream =
KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc, kafkaParams, Set("nums")
)
// 对于每个批次内出现字母的次数进行统计, 然后输出
val alphaCountDStream = kafkaDirectStream.map(_._2).map { alphabet =>
alphabet -> 1
}.reduceByKey(_ + _)
alphaCountDStream.print()
ssc.start()
ssc.awaitTermination()
上述程序的逻辑非常简单,从Kafka中获取当前批次的字母,然后统计出现次数并且输出。大致可以分为三个阶段:
1. 构建StreamingContext并初始化一系列重要的组件
在StreamingContext初始化的同时,以下几个也同时被初始化了:
- DStreamGraph,用于维护DStream之间的关系,比如说一次计算的输入DStream是哪些,输出DStream又是哪些。初始化的时候inputStreams与outputStreams皆为空。
- JobScheduler,用于DStream中的任务调度,在它初始化的时候也有一系列重要的组件被初始化,比如说JobGenerator,用于生成每个批次的任务。
- JobGenerator在初始化的时候,生成了一个定时触发任务生成的timer。在JobGenerator被启动之后,会每隔一段时间(duration)就会通过DStreamGraph来生成当前批次的任务,第一次任务触发就是离启动时间点最近的一个时间点,比如说duration是15min,启动时间为20:23,那么任务触发的时间就是20:30,之后会在20:45,21:00等时间点依次触发任务。
我们前面提到了DStreamGraph在初始化的时候inputStreams与outputStreams皆为空,但是在JobGenerator触发任务之前,DStream通过各种转换(map, filter等)和输出操作(output operation, like print),已经在DStreamGraph中注册了涉及到各种Input&OutStreams,所以为graph.generateJobs调用提供了基础 – 因为Job的产生是基于Stream的。
2. 构建DStream之间的依赖(dependency)
和RDD一样,DStream都会或多或少的产生依赖。每次的转换操作或是输出操作都会产生新的DStream,进而和原来DStream产生父子关系。最后print为DStream的输出操作,它只是将ForEachStream在DStreamGraph中注册为OutputStream,和RDD action操作不一样的地方是,此处并没有触发ForEachStream的计算,真正的计算是发生在JobGenerator在指定时间点产生Job的时候。
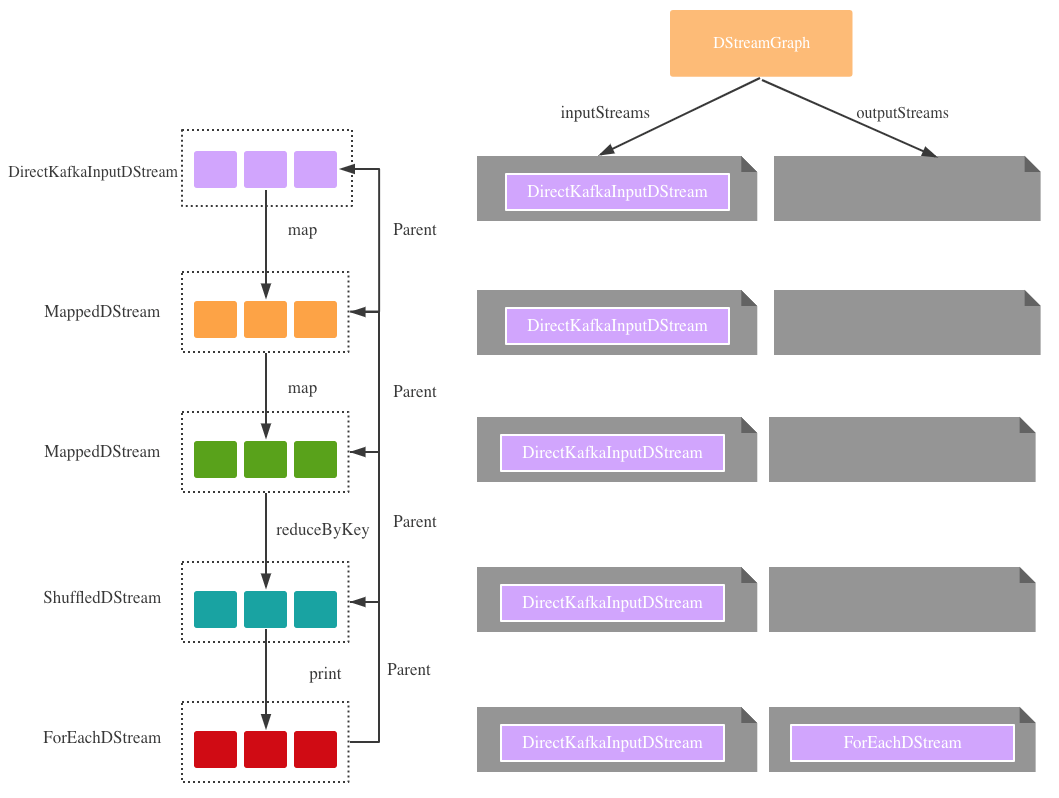
图1.DStream之间的依赖关系以及DStreamGraph的变化
3. 启动流式程序并且在指定时间点开始周而复始的计算
StreamingContext的启动,触发了JobScheduler以及JobGenerator的启动。
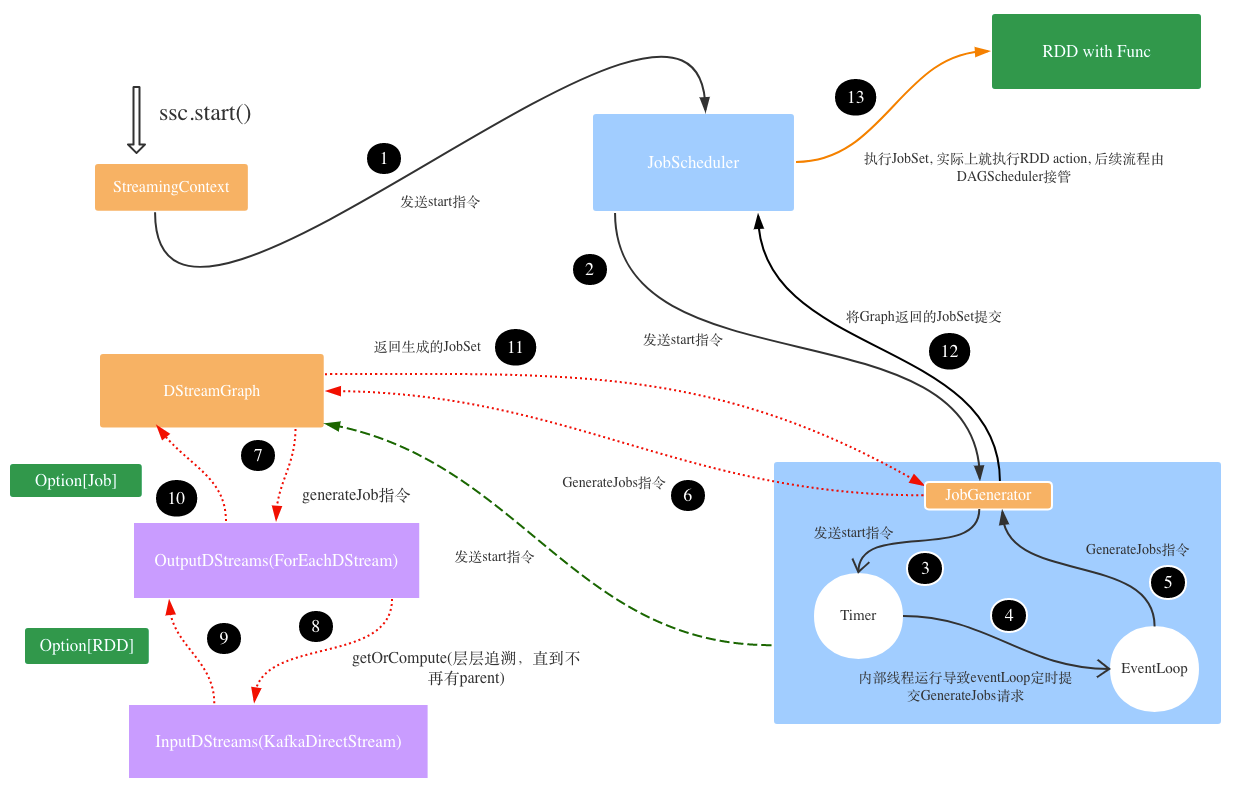
图2.StreamingContext启动之后生成任务并提交的流程
3.1 JobScheduler
JobScheduler启动的时候,内部的JobGenerator也启动了,它会按照指定间隔向JobScheduler提交任务(封装成了org.apache.spark.streaming.scheduler.JobSet)。之后JobScheduler便调用底层的线程池开始执行Job(jobExecutor.execute(new JobHandler(job)))。
3.2 JobGenerator
JobGenerator的主要任务是生成当前批次的JobSet,并且提交给JobScheduler执行,大致可以分为如下几个过程:
- JobGenerator启动时触发了内部timer不断向eventloop提交GenerateJobs指令的过程(每个interval一次),最终导致JobGenerator的generateJobs被周期性调用。
-
JobGenerator的generateJobs主要做了两件事:
- 将任务的生成进一步delegate给DStreamGraph执行,graph.generateJobs(time)
- 将生成并封装好的JobSet交由所属的JobScheduler执行,jobScheduler.submitJobSet
// org.apache.spark.streaming.scheduler.JobGenerator
private val timer = new RecurringTimer(
clock, ssc.graph.batchDuration.milliseconds,
longTime => eventLoop.post(GenerateJobs(new Time(longTime))),
"JobGenerator"
)
timer.start() -> thread.start()
// org.apache.spark.streaming.util.RecurringTimer
private val thread = new Thread("RecurringTimer - " + name) {
setDaemon(true)
override def run() { loop }
}
private def loop() {
...
while (!stoped) {
triggerActionForNextInterval
}
triggerActionForNextInterval
...
}
def triggerActionForNextInterval() {
...
clock.waitTillTime(nextTime)
// longTime => eventLoop.post(GenerateJobs(new Time(longTime)))
callback(nextTime)
...
}
代码片段1. JobGenerator循环提交任务的基本流程
3.3 DStreamGraph
DStreamGraph根据维护的OutputStream以及它的依赖关系开始生成最终任务所对应的RDD,在开篇已经提到过,DStream的计算本质上是RDD的计算。
ForeachDStream不断调用父类DStream的compute方法生成相应的RDD,直到根类,在本例中也就是DirectKafkaInputDStream。当DirectKafkaInputDStream的compute方法被调用后生成Option[KafkaRDD],然后逐级返回,分别将子DStream所对应的函数施加在Option[KafkaRDD]上面,最终变成ShuffledRDD,并根据相应的缓存级别(storageLevel)缓存生成的RDD(newRDD.persist(storageLevel)),如果有需要也会进行相应的checkpoint(newRDD.checkpoint())。
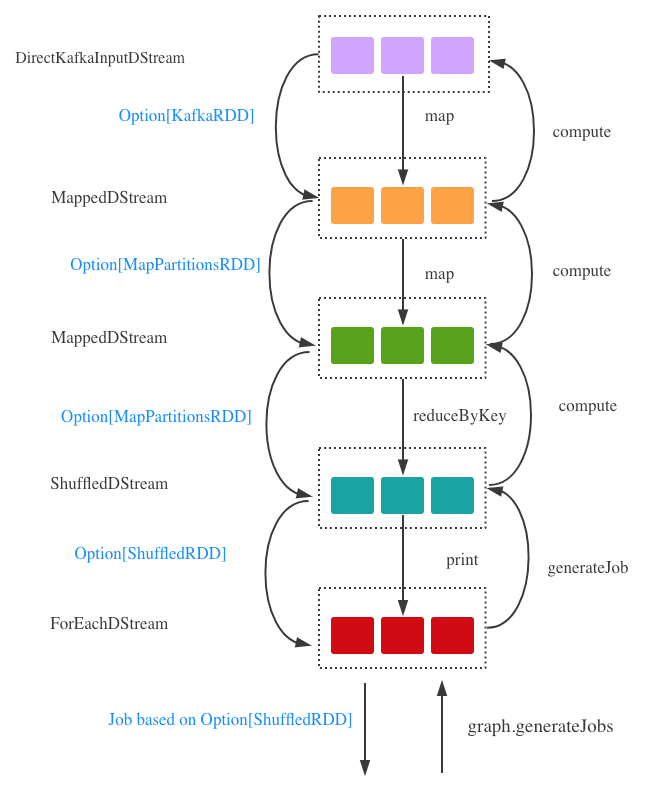
图3.DStreamGraph生成Job的过程
在上述生成ShuffledRDD过程中,RDD之间的依赖关系也已经形成,相当于DStreamGraph转换成了RDDGraph,为后面JobScheduler计算RDD做好了准备。
当JobScheduler接收到JobGenerator提交的任务之后,实际上就已经进入RDD的执行过程,在本例中就是打印出每个字母出现的次数。由于JobGenerator内部的triggerActionForNextInterval是定期运行的,所以生成JobSet,提交给JobScheduler运行的过程会一直执行下去。
4. 批次计算完成之后的收尾工作
JobScheduler在完成任务(Job)的执行之后,主要进行下列几项工作:
- 向内部的eventloop发出JobCompleted指令,从jobSets中移除完成的Job
-
JobGenerator开始清除元数据,进而导致DStreamGraph清除元数据,即清除outputStreams产生的RDD以及它们的缓存,还有outputStreams父类产生的RDD以及缓存的RDD。
- 产生的RDD指的是上面的提到的每当DSteam调用getOrCompute的时候,就将产生的RDD放入内部维护的generatedRDDs中,实际上是一个批次时间到RDD的映射。在清除的时候将对应批次的RDD从Map中移除
- 从缓存中移除即调用
rdd.unpersist(true)
总结
流式计算的本质是定时RDD的计算,也就是持续的RDD计算。整个计算就是DStreamGraph –> RDD Graph –> RDD Job的过程。涉及到两个层面的调度: JobSheduler用于DStream生成Job, DAGScheduler用于RDD的计算。