通用情况下我们会使用
sc.textFile(...)读取HDFS文件,以前一直以为如果不传递numPartition就会根据HDFS的块大小进行分区划分;如果传递了,就会按照numPartition进行划分,但不幸的是,这种理解是错误的。
今天的开发的时候从HDFS中读取文件,读取的目录大概有64个文件(dfs.blockSize=128M), 每个大小约380M左右,
sc.textFile("/path/xx", 100).partitions.size
期待是100, 结果却是192。于是再次阅读了相关部分的源码,遂对这个问题有了一个清晰的认识。
实际上我们传递的这个参数指的是理论上最小的分区数, 也就是说如果文件总大小为TotalFileSize, 那么如果按照TotalFileSize / NumPartition进行文件切分那么正好就可以满足NumPartition个分区。
但是由于读取的是HDFS文件,所以还需要将HDFS的块大小(BlockSize)和传递的切分单元(每个分区中多少字节的记录)考虑进去。org.apache.hadoop.mapred.FileInputFormat中的getSplits也体现了这一逻辑。总而言之,分区数大小就是由上面三者共同决定的, 基本流程就是:
- 计算HDFS中所有文件的总大小(TotalLen)
- 计算理想拆分单元GoalSize(GoalSize = TotalLen / NumPartition)
- 将理想拆分单元GoalSize,与BlockSize,HDFS MinSplitSize进行比较,得出最终的拆分单元ResultSize(
ResultSize = Max(HDFS MinSplitSize, Min(GoalSize, BlockSize))) - 遍历HDFS中的文件,依次按照ResultSize进行切分,然后构造InputSplit对象。当剩余的大小Remaining与ResultSize达到某种比例时,则停止;剩下的则再单独生成一个InputSplit对象。
在我的案例中(380 * 64 / 100)M > 128M(HDFS MinSplitSize = 1), 所以最终应该是以128m作为切分单元。因此,每个文件被拆分了3个分区,最终形成192个分区。
// org.apache.hadoop.mapred.FileInputFormat;
public static final String SPLIT_MINSIZE =
"mapreduce.input.fileinputformat.split.minsize";
public InputSplit[] getSplits(JobConf job, int numSplits) {
...
private static final double SPLIT_SLOP = 1.1; // 10% slop
// 最小的切分单元大小(字节)
private long minSplitSize = 1;
// 目标切分单元大小 -- 380M * 64 / 100
long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits);
// 根据用户的配置来确定切分单元大小
long minSize = Math.max(job.getLong(org.apache.hadoop.mapreduce.lib.input.
FileInputFormat.SPLIT_MINSIZE, 1), minSplitSize);
// 遍历文件系统的文件,对于每一个文件按照计算的拆分单元进行切分
for (FileStatus file: files) {
...
long length = file.getLen();
// 获取HDFS的BlockSize大小
long blockSize = file.getBlockSize();
// Math.max(minSize, Math.min(goalSize, blockSize))
// 先计算goalSize和blockSize之间最小的,然后将结果与minSize比较取最大的
long splitSize = computeSplitSize(goalSize, minSize, blockSize);
long bytesRemaining = length;
// 下面的逻辑就是按照切分单元进行切分,如果剩余的空间比切分单元多不到10%,则停止
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
splits.add(...)
bytesRemaining -= splitSize;
}
// 如果还有剩余的,则新增一个InputSplit。 如果bytesRemaining比splitSize小很多,
// 那么这个分区中的记录会明显比其它分区中的少。如果出现这种情况,可以通过coalesce或repartition去手动调整。
if (bytesRemaining != 0) {
splits.add(...);
}
}
}
上述的拆分过程基本如下图所示(Block与InputSplit的数量并不是一一对应的):
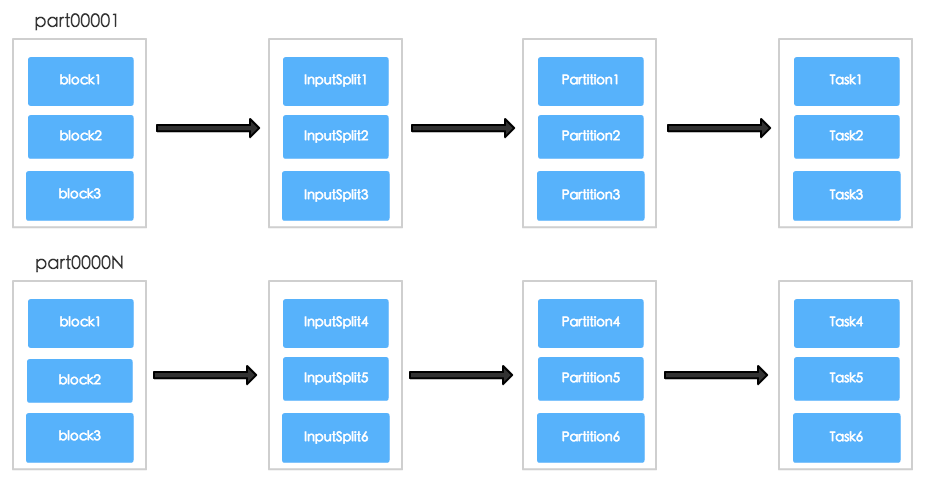
弄清楚初始分区数大小之后,我们就能够确定在不同阶段(Stage)分区的大小,这样也能够确定每个阶段的任务数和并行度,也可以更好的指导我们去设置num-executors和executor-cores。