1. 是什么
Transactions are atomic units of work that can be committed or rolled back. When a transaction makes multiple changes to the database, either all the changes succeed when the transaction is committed, or all the changes are undone when the transaction is rolled back.
事务(transaction)是一系列由SQL语句组成的逻辑性操作,当一个事务中的SQL语句对于数据库进行多次改动,要么所有的改动全部生效(commit)、要么所有的改动全部撤销(rollback),同时这些改动会永久存储到 稳定的存储中(磁盘或者是其它存储)。
数据库四大特性 ACID
1.1 原子性 – Atomicity
要么失败要么成功,all or nothing。比如说一笔转账要么成功,要么失败,不存在中间状态。
主要涉及到如下方面:
- autocommit设置
- commit & rollback
1.2 一致性 – Consistency
数据的状态应该从一个正确的状态转换到另外一个状态。
- 从数据模型的体现就是约束(contraint),比如说Column字段类型、长度、外键约束等(
存疑) - 另外就是故障恢复层面,比如说提交事务的时候,机器突然挂了也要保证状态正确(比如说redo log commit的时候奔溃,恢复时如何保证对应事务的状态正确), 我们一般提到的一致性是指的这个方面
关于原子性和一致性有时可能会混淆,可以通过这个场景去区分: 原子性能保证要么转账成功,要么转账失败,但是它不能保证转账之后,整个借贷(sum of all debits and credits)之和为0(某一方支出100,某一方收到100)。
关于crash recovery主要涉及到如下方面:
- The InnoDB doublewrite buffer
- InnoDB crash recovery
1.3 隔离性 – Isolation
一个事务的操作对于其它事务的可见性程度,比如说一个事务的更改对于其它的正在运行的事务,是可见的的还是不可见的。
关于隔离主要涉及到如下方面: Read view + Undo log版本链
1.4 持久性 – Durablity
一个事务提交之后,它的所有操作需要被持久化到数据库中(即使是断电或是其它的异常),但是这个属性实际上是有一个级别要求的,不然为什么还有备库的需求。
同时也是涉及方面最多的,因为部署机器本身的一些硬件因素也会被考虑。它和原子性也是事务中密切相关的两个属性。
关于持久性支持主要涉及到如下方面:
- Redo log – 这个实际上是基于ARISE理论提出来,具体的呈现也就是Write-Ahead Logging
Algorithms for Recovery and Isolation Exploiting Semantics,ARIES
基于语义的恢复和隔离算法
IBM Almaden 研究院总结了研发原型数据库系统”IBM System R”的经验,发表了 ARIES 理论中最主要的三篇论文,其中
ARISES: A transaction recovery method supporting fine-granularity locking and partial rollbacks using write-ahead logging
着重解决了原子性(A) 和 持久性(D)
和大多数DBMS一样,InnoDB 也遵循WAL(Write-Ahead Logging)的原则,在写数据文件前,总是保证日志已经写到了磁盘上(buffer pool page修改后于redo log落盘)。
通过Redo日志可以恢复出所有的数据页变更
- The operating system used to run MySQL, in particular its support for the fsync() system call.
- A battery-backed cache in a storage device – 充放电
- The write buffer in a storage device, such as a disk drive, SSD, or RAID array.
2. 事务ID(transaction id)
MySQL Server全局递增的数字类型的值,用于标识每一个事务,在MVCC中有重要用途。
- 分配的时机(MySQL 5.7) – begin之后运行第一个SQL语句(CURD)
mysql> begin;
Query OK, 0 rows affected (0.01 sec)
mysql> SELECT tx.trx_id FROM information_schema.innodb_trx tx WHERE tx.trx_mysql_thread_id = connection_id();
Empty set (0.01 sec)
mysql> select * from black_list;
Empty set (0.00 sec)
mysql> SELECT tx.trx_id FROM information_schema.innodb_trx tx WHERE tx.trx_mysql_thread_id = connection_id();
+-----------------+
| trx_id |
+-----------------+
| 421459449804240 |
+-----------------+
启动事务的时候,同时开启一致性快照
mysql> start transaction with consistent snapshot;
Query OK, 0 rows affected (0.02 sec)
mysql> SELECT tx.trx_id FROM information_schema.innodb_trx tx WHERE tx.trx_mysql_thread_id = connection_id();
+-----------------+
| trx_id |
+-----------------+
| 421459449804240 |
+-----------------+
1 row in set (0.01 sec)
3. 事务隔离级别
定义了多个事务并发运行时的隔离程度以及如何互相影响
3.1 READ_UNCOMMITTED: 读取未提交事务
也就是我们常说的脏读(读取是别的事务正在进行中的修改),显然这种事务方式很少在实际中使用。
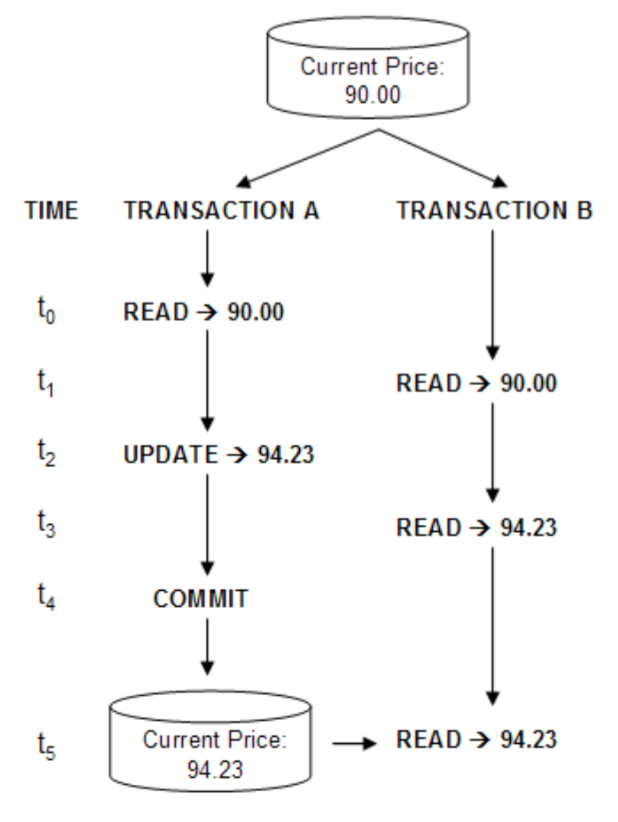
3.2 READ_COMMITTED: 读取已提交的事务的内容
这一级别是大多数数据库的默认事务级别(但并不是MySQL的)。 在一个事务开始前,它只能看到之前已经成功提交的事务的内容。当然它自己的修改也要等到提交之后才能被其它事务看见。这一级别也称为不可重复的读(nonrepeatable read) – This means you can run the same statement twice and see different data
在事务B中,对于某条记录不断读取,在另外一个事务A中,对它进行修改并提交,则可以在看到更新。
这也就是为什么这种隔离级别被称之为不可重复读(unrepeatble_read),因为会获取已提交事务的改变
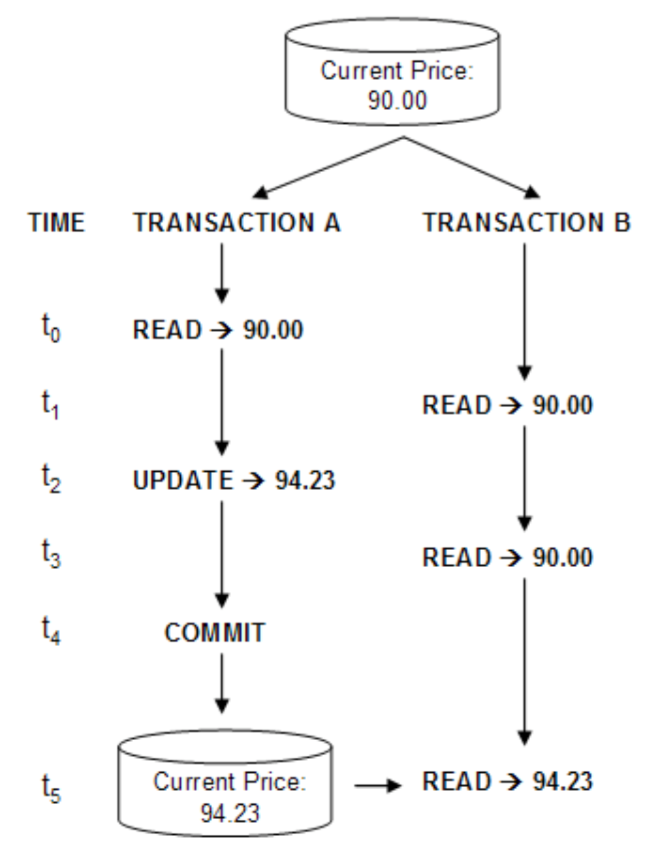
3.3 REPEATABLE_READ: 可重复读
确保在同一个事务中的对行读取始终返回同样的内容。它解决了READ_UNCOMMITTED的脏读问题。
在同一个事务中,consistent read都是使用第一次读取时候的快照。
对于不加锁的普通查询(consistent nonlocking reads),确保每次事务读取的东西都是一致的。
对于加锁查询(locking reads select with for update or for share),使用锁的策略取决查询条件:
- 如果查询条件使用了唯一索引以及选择相应的查询字段作为条件,间隙锁退化为行锁
For other search conditions, InnoDB locks the index range scanned, using gap locks or next-key locks to block insertions by other sessions into the gaps covered by the range. For information about gap locks and next-key locks, see Section 15.7.1, “InnoDB Locking”.
- 针对范围查询,InnoDB将会使用Gap Locks或者Next Key Locks锁定扫描到的Index Range, 这样阻止像这个区间进行记录插入。
但是在早期版本带来了另外一个更为棘手的问题: 幻读(phantom reads)
幻读: 当你在一个事务中选择了一系列行(range of rows),然后其它事务在这个区间插入了一些行,再次读取时,你将会看到那些行;不过InnoDB引擎通过Next-Key Lock锁解决了幻读的问题。
显然可重复读,在上一隔离级别上更进了一步。同样的情况下,在事务B中不断读取是看不到A事务产生的改变,即使A提交了也无法看到,只有等事务B自己提交后才能看见
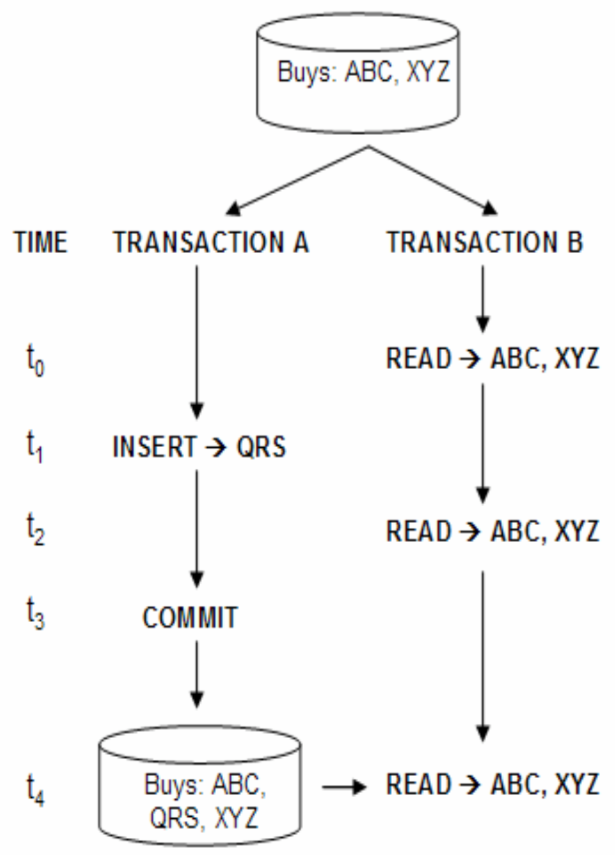
3.4 SERIALIZABLE: 串行化事务 – 几乎不会用
在MySQL(>=5.7)中,这个事务有点类似与可重复读事务。InnoDB在autocommit被禁止的情况下,隐式的将所有的普通查询语句转换成了select .. from .. lock in share mode
这就意味着同时开启两个事务,查询操作可以同时执行,说明是共享锁;
这样的话,如果谁先获取了这把共享锁,另外一个事务再进行更新操作就会被挂起,也就是尝试获取写锁的操作会等待,因为读写锁互斥。
mysql> update customer set customer_name = 'Big Huge Big Huge' where customer_number = 1;
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
This level is like
REPEATABLE READ, butInnoDBimplicitly converts all plainSELECTstatements toSELECT ... FOR SHAREifautocommitis disabledTo force a plain
SELECTto block if other transactions have modified the selected rows, disableautocommit
3.5 多个事务同时执行可能产生的问题概述
脏读: A事务读取到自己没有做出改动的数据, 比如说某个column原值为A, 然后B事务进行了修改, 变成了B, 结果A看到了-
脏写: A、B事务同时对于同时一份数据进行了修改,A事务改成A,B事务改成B(但B事务还没有提交), 结果A事务回滚把B事务更改的值也搞没了 -
不可重复读: A、B事务同时对于同时一份数据进行了读写,B事务改成B(但B事务还没有提交),A看到的还是原来的数据,但是B突然提交了事务,然后A看到的就是B事务提交后的值。 也就是A事务,
反复读取同一份数据发生了变化 - 幻读(phantom read): 相较于脏读,主要是指同一个事务,多次读取,发现了之前没有的数据,
侧重于新增
最后一张表总结一下:
| 类型 | 说明 | 可能产生的影响 |
|---|---|---|
| READ_UNCOMMITTED | 读取未提交事务 | 脏读、脏写、不可重复读、 |
| READ_COMMITTED | 读取已提交的事务的内容 | 不可重复读、幻读 |
| REPEATABLE READ | 一个事务执行过程中看到的数据,总是跟这个事务在启动时看到的数据是一致的(一次一致性快照) | 幻读 |
| SERIALIZABLE | 顾名思义是对于同一行记录,”写”会加”写锁”,”读”会加”读锁”。 当出现读写锁冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行 |
无 |
3.6 乐观锁和 MVCC 的区别
保证数据一致性的策略,MVCC侧重与对于并发读写的控制,乐观锁侧重于对于写写的控制
4. 可重复读隔离级别
由于MySQL的默认事务是可重复读,所以我们重点来看看可重复读是如何实现的?
4.1 核心就是一致性读(consistent read、transaction consistent snapshot)
也就是我们经常听到的快照读,事务在开启的时候,会对当前库拍个快照,作为当前事务在运行区间能够看到的一个状态。
创建一致性快照的时机是:
-
start transaction/begin — 执行第一条命令之后,开启事务(分配新的事务ID),创建快照
-
指定语法 start transaction with consistent snapshot
具体而言,每个事务都有一个唯一的事务ID(row
trx_id),每次更新成功会将该transaction id作为行的最新版本,与此同时旧的版本也需要保留,回滚的时候需要
所以快照本质是获取数据版本号,因此不需要存储对应的数据,而是使用当前版本结合 undo log,在需要的时候重做回到某个版本。
至于上面提到的事务在运行区间能够看到的一个状态,包括如下几个部分(主要是针对查询):
- 快照创建时,已经提交的版本(历史版本),可见
- 版本已提交,但是是在
快照创建之前提交的,可见 - 版本已提交,但是是在
快照创建之后提交的,不可见
4.2 事务更新数据的时候,只能用当前读(locking read)
即拿到数据中的最新版本,这个其实很好理解,如果A事务更新了某行并提交,但是B事务不拿到最新的版本,一旦B事务更新成功,那A事务的提交不就被覆盖了嘛。
4.3 如果更新当前记录时,行锁被其它事务占有,则需要等待其它事务释放锁
这也就是上面提到的MVCC侧重于读写控制原因,显然与锁结合也是能控制写写的并发访问。一般来说,另外一个事务尝试更新会被因为等待相关记录的锁而被阻塞,等待A释放锁然后再次尝试获取,读取最新记录然后再更新
5. 多版本机制(InnoDB Multi-Versioning)
InnoDB是一个多版本的存储引擎。每当行发生变化的时候就是记录一个版本,后续可用于支持并发访问和回滚。
版本信息(当前版本做了哪些改动)是以undo log的形式存储在undo tablespace,也就是我们常听说的回滚段(rollback segment)。
InnoDB会使用回滚段中的信息来进行回滚(roll back)也就是执行undo操作。
5.1 数据列结构 – 前置准备
为了支持多版本机制,InnoDB在每一个数据列上额外新增了三个隐藏字段:
| 列名 | 类型 | 说明 |
|---|---|---|
| DB_TRX_ID(事务ID) | 6-byte | 每次插入行或者对于行更新的时候就会更新该属性(删除也是一种特殊的更新) |
| DB_ROLL_ID(回滚段中记录指针) | 7-byte | 指向回滚段内的undo log record,相当于指向当次事务做了什么操作,这样后面才能对应的进行恢复 |
| DB_ROW_ID | 6-byte | 在行没有显示指定索引的情况(无主键、也没有唯一索引),会生成一个单调递增的row ID |
If the row was updated, the undo log record contains the information necessary to rebuild the content of the row before it was updated
MySQlL 8.0中支持使用如下命令查看:
SHOW EXTENDED COLUMNs from xxx
created_at timestamp NO CURRENT_TIMESTAMP DEFAULT_GENERATED
updated_at timestamp NO CURRENT_TIMESTAMP DEFAULT_GENERATED on update CURRENT_TIMESTAMP
DB_TRX_ID NO
DB_ROLL_PTR NO
5.2 Read view - 记录相关的事务ID
ReadView可以理解为开启时候的时候,基于查询条件,对于当前表保存的一个快照。相关的底层实现在read0read.cc
Read view lists the trx ids of those transactions for which a consistent read should not see the modifications to the database.
| 字段(ReadView类中私有属性) | 含义 | 说明 |
|---|---|---|
| m_low_limit_id: trx_id_t | 高水位线,类似于 Kafka high watermark |
The read should not see any transaction with trx id >= this value 读取的时候,大于等于该值的事务都不可见; 取值为下一个待分配的事务ID,也就是就是max(m_ids) + 1 |
| m_up_limit_id: trx_id_t | 能被当前事务看到改动的tx_id最大值(exclusive) | The read should see all trx ids which are strictly smaller (<) than this value。In other words, this is the low watermark 当事务ID小于这个值的时候,表示在创建该read view前,记录的事务已经提交 该记录可见,取值为还没提交的事务ID中最小的一个 min(m_ids) |
| m_creator_trx_id: trx_id_t | 当前session的对应的事务ID | trx id of creating transaction 当前事务的ID, 如果当前记录的事务id和这个一样,可以看见 |
| m_low_limit_no | 当事务小于这个值的时候,这些undo logs可以通过purge操作移除 | The view does not need to see the undo logs for transactions whose transaction number is strictly smaller (<) than this value: they can be removed in purge if not needed by other views. |
| m_ids | 快照创建的时候的 所有活跃的事务ID, 也就是没有提交的 |
Set of RW transactions that was active when this snapshot was taken |
5.2.1 新建一个ReadView
/**
Opens a read view where exactly the transactions serialized before this point in time are seen in the view.
@param id Creator transaction id
*/
void ReadView::prepare(trx_id_t id) {
/**
* 私有变量creator_id 就等于 当前开启ReadView的 事务
*/
m_creator_trx_id = id;
/**
* high watermark就是取的当前s max_trx_id
*/
m_low_limit_no = m_low_limit_id = trx_sys->max_trx_id;
}
max_trx_id 定义中提到当前还未被分配给事务ID的最小值,max(active_ids) + 1 看上去也没有什么问题
The smallest number not yet assigned as a transaction id or transaction number. This is declared volatile because it can be accessed without holding any mutex during AC-NL-RO view creation
5.2.2 完成ReadView创建
void ReadView::complete() {
/*
The first active transaction has the smallest id.
*/
m_up_limit_id = !m_ids.empty() ? m_ids.front() : m_low_limit_id;
}
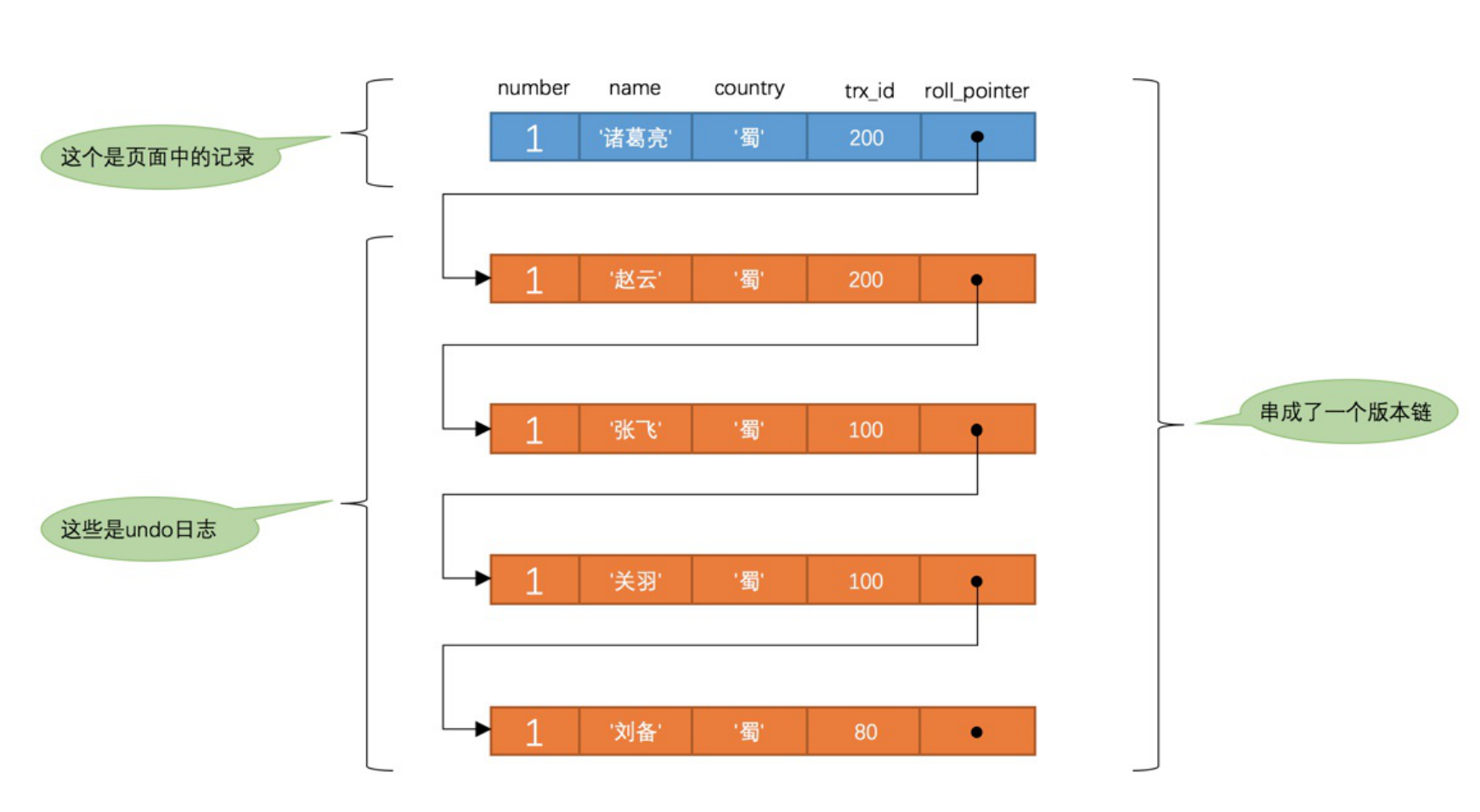
5.3 Undo log版本链 – 基于undo log形成
InnoDB在每个对于数据进行更改之后,就会生成一条新的记录,同时记录是哪个事务做了这次修改同时会生成一条undo log,新的记录中的roll_pointer会指向undo log中的对应日志。 每一次更改都会做出同样的操作,这样就会形成一个链表头为当前记录的链表。
5.4 MVCC – 多版本并发访问(read0read.h)
MVCC works only with the REPEATABLE READ and READ COMMITTED isolation levels
有了4.1 ~ 4.3的铺垫,其实MVCC的实现大概原理就已经清晰了,就是基于Read view和Undo log版本链来实现的。
- 创建Read view
每次开启的事务的时候,会创建一个ReadView,里面会维护当前活跃的事务id(m_ids)、低水位事务id(m_up_limit_id – 也就是活跃中最小的)、高水位事务id(当前最大事务id + 1),当前事务id等信息
- 改动日志产生undo log, 基于roll_pointer形成undo log chain
对于记录进行改动(以更改为例),会同时生成一条undo log, 记录发生变化之前的值,然后新的记录中的roll_pointer会指向undo log对应的记录。
-
然后当前事务再读取数据时候,会查看指定行的隐藏列(trx_id) 同时结合自己创建ReadView,根据相应的规则来判断这条记录对于当前事务是否可见
-
这样不同的事务就可以对于不同的版本进行读取和当前的记录进行更新,互相不干扰,这样就是实现了多版本并发访问
那么是如何读取之前的版本的呢?
在Locking Read的官方文档有这样一段话,说明了读取老版本的原理。也就是基于内存的当前记录 + 重做日志 回到对应版本
Old versions of a record cannot be locked; they are reconstructed by applying
undo logs on an in-memory copy of the record
检查记录对于当前事务是否可见的源码:
/* read0types.h */
/**
* ! jacoffee 当前的事务的read view是否能看到 传入的事务ID的改动,有可能就是本身
* Check whether the changes by id are visible.
@param[in] id transaction id to check against the view
@param[in] name table name
@return whether the view sees the modifications of id.
*/
bool changes_visible(
trx_id_t id,
const table_name_t& name
) {
/**
* 如果待检查的事务ID(比如说当前事务尝试读取某一行的时候,发现它当前的trx_id=id)比 当前事务Read_View中的up limit还小
* 或者是 该id就是本身则 可见
*/
if (id < m_up_limit_id || id == m_creator_trx_id) {
return(true);
}
check_trx_id_sanity(id, name);
/**
* 大于等于 高水位 不可见
*/
if (id >= m_low_limit_id) {
return(false);
} else if (m_ids.empty()) {
/**
* 当前事务对应的m_ids是空的,则也是可见的
*/
return(true);
}
/**
* 返回当前活跃的 事务IDs
*/
const ids_t::value_type* p = m_ids.data();
/**
* 二分法 判断 id 是否处于m_ids中,如果在则不可见
*/
return(!std::binary_search(p, p + m_ids.size(), id));
}
5.4.1 READ_COMMITTED是如何基于ReadView机制实现的
With READ COMMITTED isolation level, each consistent read within a transaction sets and reads its own fresh snapshot.
一句话总结: 每次查询的时候都重新生成一次ReadView, 然后基于此进行判断*
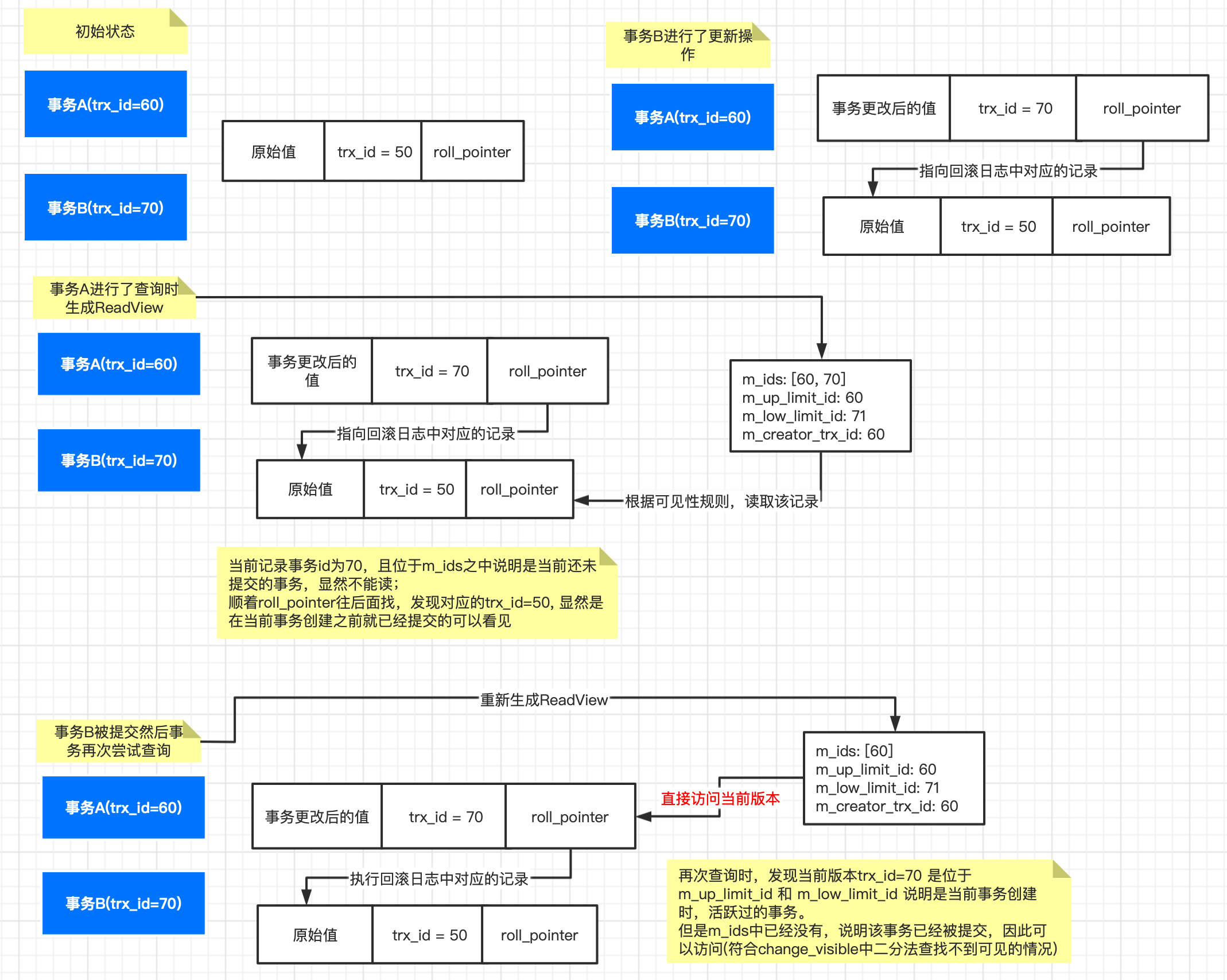
5.4.2 REPEATABLE_READ(RR)是如何基于ReadView机制实现的
If the transaction isolation level is REPEATABLE READ (the default level), all consistent reads within the same transaction read the snapshot established by the first such read in that transaction
一句话总结: 事务始终使用首次查询时生成的ReadView。
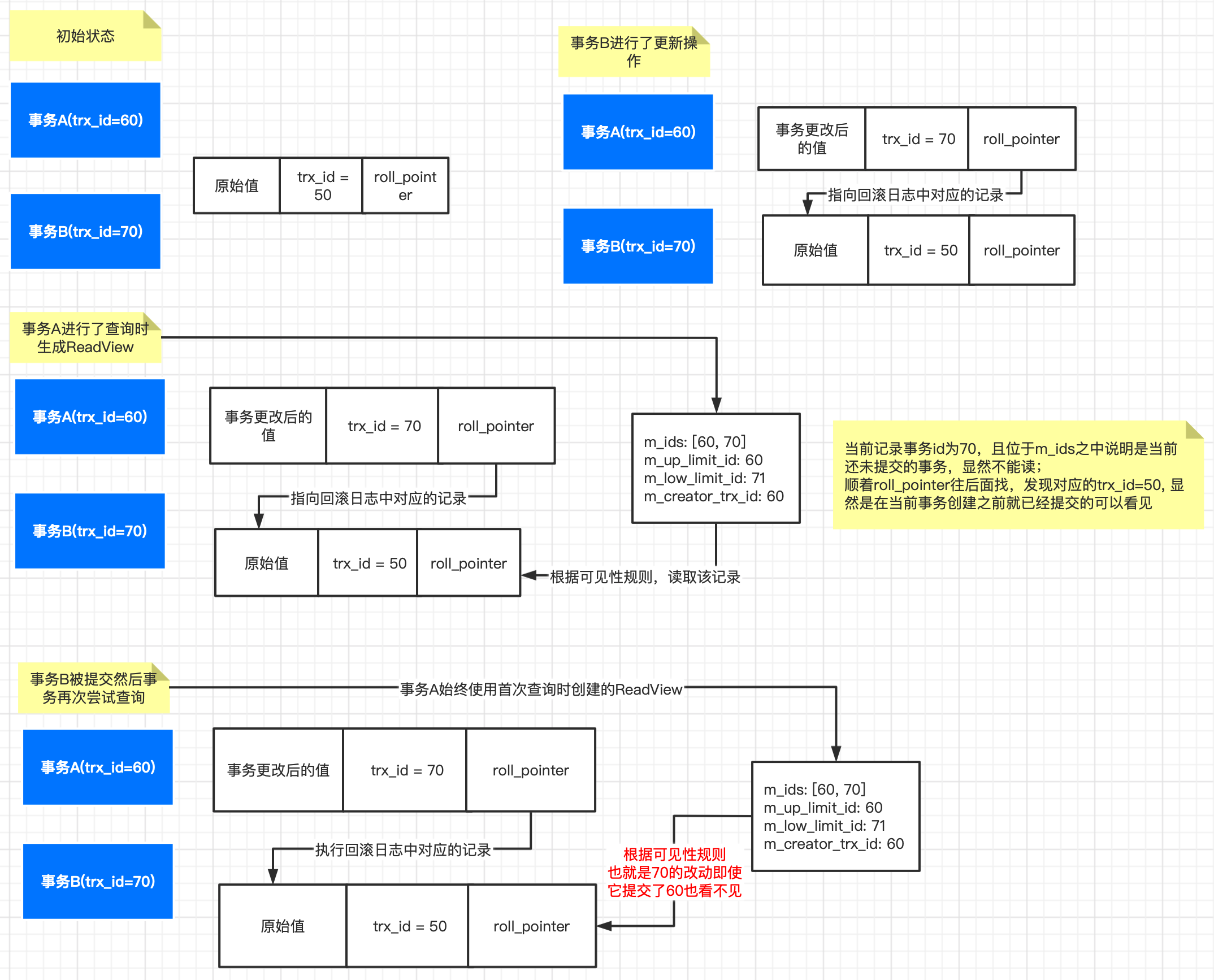
6. 快照读(consistent nonlocking read)
6.1 定义
A consistent read means that InnoDB uses multi-versioning to present to a query a snapshot of the database at a point of time
查询的数据是当前的命中记录的快照,底层来讲就是 在某一时刻给事务系统trx_sys打快照, 把当时的trx_sys状态(包括活跃读写事务数组)记下来,之后的所有读操作根据其事务ID(即trx_id) 与snapshot中的 trx_sys的状态作比较,以此判断ReadView对于事务的可见性。
6.2 核心特点
不会在访问的表记录上加锁因此其它事务也可以同时间修改表- 在获取ReadView之后(RR模式 Suppose that you are running in the default
REPEATABLE READisolation level),如果其它事务删除、更新或者是新增了某些记录,当前事务(Select操作)是感知不到的 - 但如果在当前事务尝试更新,一定会尝试读取最新的版本,
同时当其它事务正在更新的时候,当前事务尝试更新会被阻塞,这也就是后面当前读的特性
6.3 在什么场景下会失效
- 如果其它事务将表删除了(drop table) ,因为MySQL不能使用已经被删除的表(InnoDB destroys the table)
- 如果其它事务执行alter table之类的命令
In this case, the transaction returns an error:
ER_TABLE_DEF_CHANGED, “Table definition has changed, please retry transaction”
7. 当前读(locking read) - 前提autocommit off
这个地方让我再次感受到外文文档重要,当前读是翻译过来的,但是去没有清晰的表达locking read的含义。因此对于重要的组件和项目,最好从阅读外文文档开始。
- 来源
如果你想要对于查询的数据进行更新等操作,普通的查询是无法提供足够的一致性保证的。因为其它事务可以对于你查询过的数据进行修改。因此MySQL提供了两种保障程度更高的方式。
Locking reads are only possible when autocommit is disabled (either by beginning transaction with
START TRANSACTIONor by settingautocommitto 0.
-
前提 –
需要将关闭自动提交,才能生效 -
子查询方面
只对于外层查询的表有作用,除非嵌套查询中的表,也同样locking read
/* 不会对于t2记录加锁 */
SELECT * FROM t1 WHERE c1 = (SELECT c1 FROM t2) FOR UPDATE;
/* t2记录也会同样加锁 */
SELECT * FROM t1 WHERE c1 = (SELECT c1 FROM t2 FOR UPDATE) FOR UPDATE;
7.1 定义
重点要理解 快照读的不足以及我们为什么需要当前读
当前读 顾名思义就是 始终读取数据的最新版本。隐含的一层意思就是对于数据进行近一步的保护(避免不一致性,比如说查询数据之后再进行更新,但是其它事务对于记录做了修改)
7.2 select … for share(select … lock in share mode 8.0之前的版本)
该语句给所有读取过的记录加上了 共享锁(shared mode lock),这样当其它事务想要更改(获取exclusive lock)就必须等到当前事务释放shared mode lock。
如果当前查询的行正在被其它事务更改(也就是查询的时候获取不到锁),那么当前事务就会等待其它事务释放锁,同时读取最新的值(your query waits until that transaction ends and then uses the latest values)。
mysql> select * from article limit 10;
+----+-----------+-------------+-------+----------+-------+---------+
| id | author_id | category_id | views | comments | title | content |
+----+-----------+-------------+-------+----------+-------+---------+
| 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| 3 | 1 | 1 | 3 | 3 | 3 | 3 |
+----+-----------+-------------+-------+----------+-------+---------+
| 时间点 | 事务1 | 事务2 |
|---|---|---|
| T1 | begin; | begin; |
| T2 | update article set title = ‘测试select…for share’ where id = 2; | |
| T3 | select * from article where id = 2 lock in share mode; | |
| T4 | Blocking | |
| T5 | commit; | |
| T6 | get lock and read the latest value title = ‘测试select…for share’ |
|
| T7 | commit; |
7.3 select … for update
For index records the search encounters, locks the rows and any associated index entries, the same as if you issued an
UPDATEstatement for those rows.
查询的时候,如果扫描到索引记录,则会给相应的记录以及区间加锁(具体的规则可以参考 锁 章节对于 间隙锁规则的描述)。
官网也提到,上面两种操作比较适合,那种树形或者是图形结构的遍历。
These clauses are primarily useful when dealing with tree-structured or graph-structured data, either in a single table or split across multiple tables. You traverse edges or tree branches from one place to another, while reserving the right to come back and change any of these “pointer” values
8. 实战演练
8.1 影响事务延迟提交的场景
8.1.1 锁等待(lock wait)
- RR模式下的 insert等待gap lock
- Insert等待MDL
- Table lock
8.1.2 IO方面
-
慢sql导致io高
-
其他程序占用比价高
-
Buffer pool命中率比较低
-
并发导致
-
innodb buffer pool 不够用
-
update、delete更新数据行数大(>W)
8.1.3 Buffer 方面
-
Redo log buffer 是否够用通过 innodb_log_waits 确认
-
Redo log buffer 刷盘方式通过innodb_flush_log_at_trx_commit
-
Binlog cache 是否够用,创建临时文件、消耗 IO
-
Change buffer 是否够用
8.1.4 落盘延迟
-
sync_binlog 参数
-
binlog_group_commit_sync_delay 参数
-
innodb_flush_commit 参数
- 查看innodb_buffer_pool 的命中率,查看脏页刷新频率效果
- 磁盘空间不足,导致落盘失败
8.2 InnoDB存储引擎针对事务的抽象 trx0trx.h
struct trx_t {
/* 事务ID */
trx_id_t id;
/* 事务的状态 */
trx_state_t state;
/* ReadView */
/*!< consistent read view used in the transaction, or NULL if not yet set */
ReadView* read_view;
/* 当前事务锁的状态 */
trx_lock_t lock; /*!< Information about the transaction
locks and state. Protected by
trx->mutex or lock_sys->mutex
or both */
}
9. 参考
> 官网 事务模型 InnoDB Transaction Model
> InnoDB Source Code Documentation
> «MySQL是怎样运行的» 事务隔离级别和MVCC 强烈推荐
> MySQL · 源码分析 · InnoDB的read view,回滚段和purge过程简介
> 简化版的导读
> InnoDB Transaction Lock and MVCC 何登成 写的很深入