分布式锁本质上解决的是进程间协调的问题(process synchronization),一般用于确保同一时间只有一个进程能对于共享的资源进行访问,也即排他锁(X)。
实现的过程中需要注意以下问题:

1. 粒度(granularity) – 锁多大范围
Java锁中,加锁得时候要注意粒度,最好不对于整个类进行加锁,只对于需要共享访问的变量加锁
类似的数据库事务进行更新或者删除数据时,需要尽量减少加锁数据的范围,比如说对于区间的确定的数据删除,可以通过加limit多次删除,而不是指定值非常大的limit。
2. 锁获取(acquisition timeout) – 获取有超时还是失败立即放弃
获取不到是立即放弃还是可以重试。这种需要考虑因为分布式框架而导致的重复获取的问题。
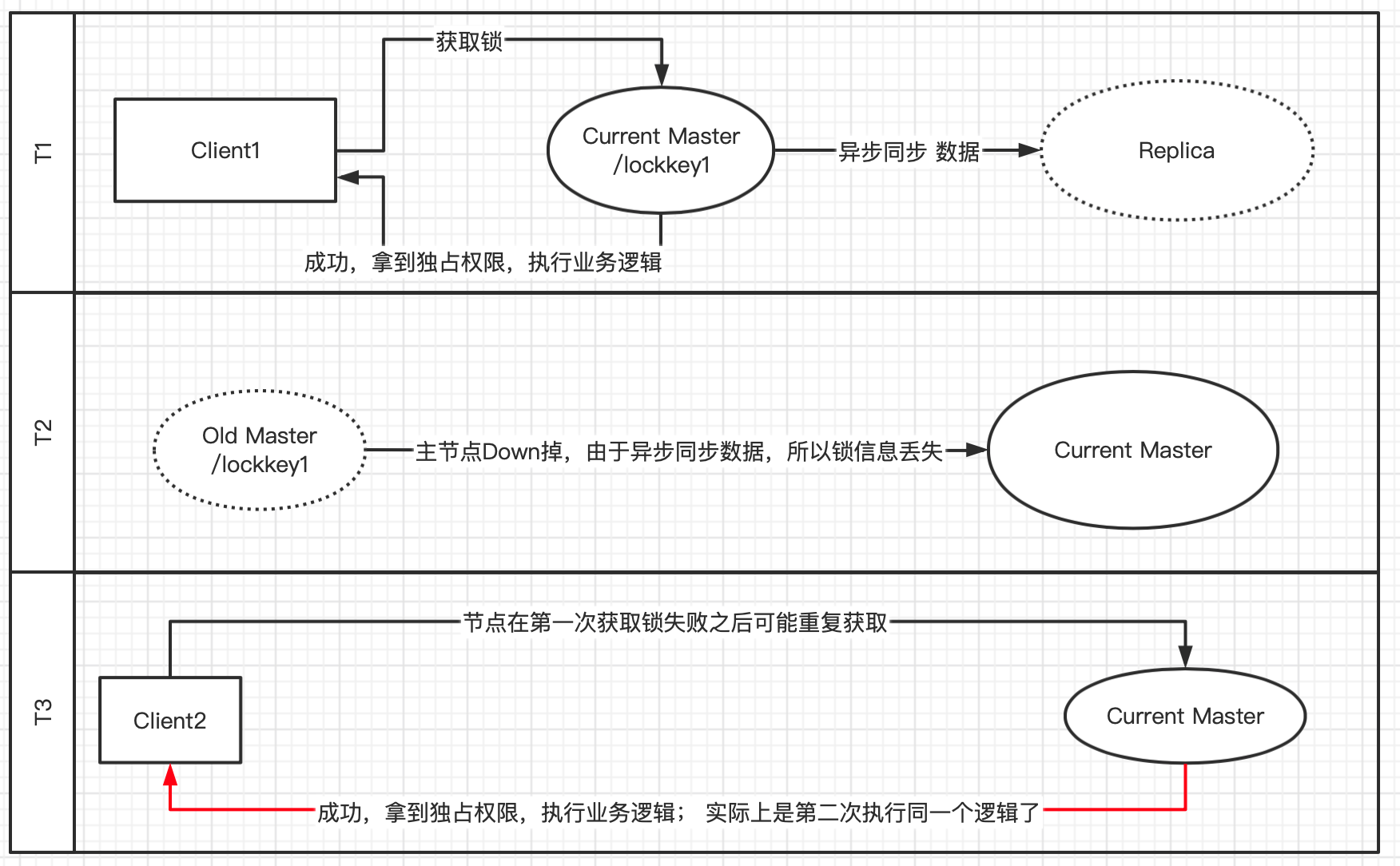
以Redis主备切换模式为例,当前主节点如果挂掉得话,由于异步复制可能副本节点还没有来得及同步锁相关的信息,从而导致多个应用同时获取锁。当然这种情况出现也是有一定场景的,高并发的获取锁、设置了锁获取超时(指定时间内重复获取锁)。
具体流程见下图:
3. 锁续期(lock renewal)
一般对于锁我们会指定过期时间,但有些场景我们希望主动释放(删除对应的路径),而不是锁过期自动释放。因此会引入续期机制,实际上就是一个线程不断去更新锁的过期时间。
4. 锁释放(lock release)
4.1 过期时间 – timeout
获取锁的主体一定要结合业务场景设置合理过期时间,确保加锁保护的执行逻辑尽量简化,这和避免长事务有异曲同工之妙。
4.2 异常释放 – release anyway
如果程序逻辑执行异常,要做好兜底的释放锁逻辑,在Java中通常是在finally块中执行删除lock key。
4.3 身份验证 – only the lock owner can release the lock
去释放锁的时候要确认的是 当前持有锁的客户端 和 释放锁的客户端 是同一个, 这种出现的一个场景是:
| 时间 | Client1 | Client2 |
|---|---|---|
| T1 | 获取锁,执行业务逻辑导致超时释放 | |
| T2 | 获取锁,开始执行逻辑 | |
| T3 | 完成业务逻辑,尝试释放锁,也就是删除对应的路径 |
这个时候,开源框架实现的时候,通常会进行身份检查,无论是基于进程还是线程级别实现的,都会分配一个唯一标识。比如说Redisson实现的,就可以基于线程级别,也就是基于线程构造唯一性标识。
5. 可重入实现(reentrancy)
Java synchronized锁和ReentrantLock都支持可重入,也就是当前持有锁得线程和 正在尝试获取锁得线程一致,则自动授予锁,并增加持有次数,也就是所谓的重入次数。
对于可重入,我们需要对于每一个获取锁的主体定义唯一标识,比如说Redisson就会基于线程ID和锁路径构造唯一标识。