数据库综述系列主要是参考CMU15-721课程中提到的Database System Report,针对个人研究过的数据库(主要是OLAP方向)的核心架构进行梳理。
1. 是什么
BusTub是一个使用C++开发的教具型关系型数据库,基于行存,以SQL生命周期的角度来看的话,主要分为以下部分:
-
SQL解析层: 基于PG的SQL解析工具libpg_query
-
SQL优化层: 基于规则的SQL优化器(RBO),但目前还比较原始,规则还比较少
在fall2023 project3的项目页中这段说明已经非常清晰的解释了 BusTub优化器实现
The BusTub optimizer is a rule-based optimizer. Most optimizer rules construct optimized plans in a bottom-up way. Because the query plan has this tree structure, before applying the optimizer rules to the current plan node, you want to first recursively apply the rules to its children.
At each plan node, you should determine if the source plan structure matches the one you are trying to optimize, and then check the attributes in that plan to see if it can be optimized into the target optimized plan structure
- SQL执行层: 基于火山模型的pull模式
另外BufferPool Manager基于ExtendibleHashTable实现了内存页管理,基于LRU-K实现了内存页置换功能;
要概览一个数据库的核心组件,一般只需要查看源码中的XXInstance,比如说BustubInstance。 里面一般会”组合”该数据库依赖的核心组件。
class BustubInstance {
private:
// 磁盘管理器,主要负责磁盘页的读写
DiskManager *disk_manager_;
BufferPoolManager *buffer_pool_manager_;
// 锁管理器
LockManager *lock_manager_;
// 事务管理器
TransactionManager *txn_manager_;
// 日志管理器
LogManager *log_manager_;
// 执行引擎
ExecutionEngine *execution_engine_;
}
在具体展开之前,以一张图展示BusTub的核心架构, 同时也体现了Spring 2022课程中各个Project具体完善了哪些模块。
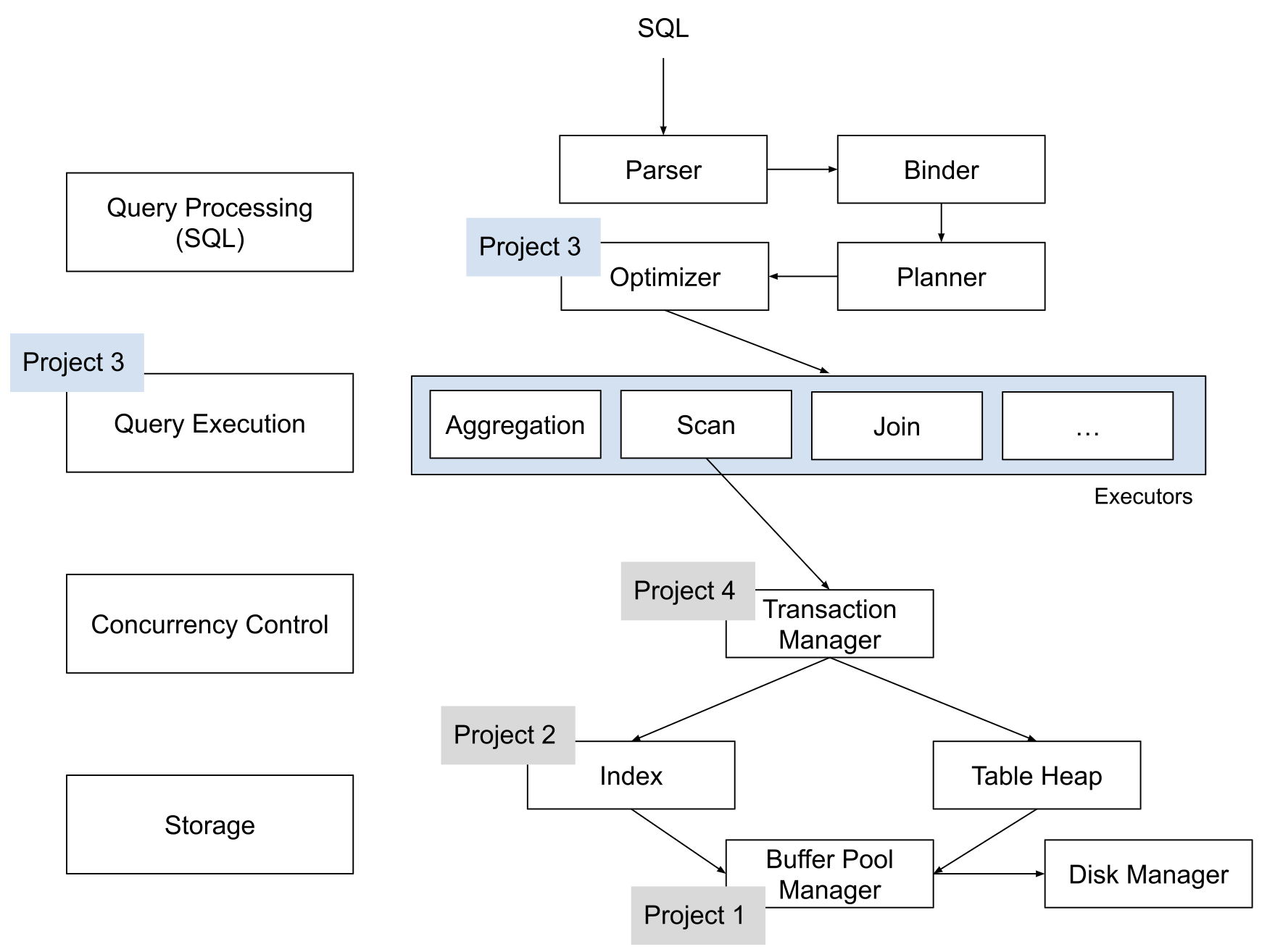
CMU15-445课程特别强调不要公开项目相关代码,所以本文展示的相关代码仅为已有的部分或者是辅助行文的关键代码片段。相关的技术点一般只是说明核心实现,不会展开具体的实现细节,毕竟只是综述。
另外由于笔者数据库水平有限,难免存在谬误,所以请带着审慎和批判的眼光阅读本文。
2. 核心技术点
以下部分主要针对课程中项目涉及的技术点进行剖析。
2.1 相关术语解释
| 术语 | 说明 |
|---|---|
| Page | 内存磁盘页的抽象 |
| Tuple | 一行数据的抽象 |
| AbstractExpression | 表达式抽象 比如说逻辑表示式、比较表达式、常数表达式 |
| LogicExpression | 逻辑表示式抽象 AND、OR |
| ComparisonExpression | 比较表达式 x = 1、x > 2、y < 3 |
| ColumnValueExpression | 某一列的表达式,记录了包括列的位置(col_index)、类型(col_type)等信息 |
| ConstantValueExpression | 常数的表达,比如说上面的 1 2 3 |
| AbstractPlanNode | 逻辑计划的抽象 |
| SeqScanPlanNode | 顺序扫描节点的抽象 |
| FilterPlanNode | 过滤节点的抽象 |
| AbstractExecutor | 物理计划的抽象 |
| SeqScanExecutor | 顺序扫描算子的抽象,最基础的算子 |
| FilterExecutor | 过滤算子的抽象 |
2.2 数据存储结构
数据库的存储结构,这里主要是指列存还是行存,很大程度的影响后续的查询执行、存储设计之类。 比如说列式存储(column-oriented storage、columnar store),我们会经常听到向量化、各种压缩等关键词,但是行存(row-oriented storage)却很少听到这些关键词。
BusTub内部page为基础单位,基本大小为4096 byte,使用字节数组(char *)存储实际数据,序列化的使用直接将字节数组落文件。每一行记录使用Tuple抽象,由offset + 实际数据组成。
class Page {
private:
// 存储实际数据
char data_[BUSTUB_PAGE_SIZE]{};
// 页ID
page_id_t page_id_ = INVALID_PAGE_ID;
}
/**
* Tuple format:
* ---------------------------------------------------------------------
* | FIXED-SIZE or VARIED-SIZED OFFSET | PAYLOAD OF VARIED-SIZED FIELD |
* ---------------------------------------------------------------------
*/
class Tuple {
void Tuple::SerializeTo(char *storage) const {
// 填充offset
memcpy(storage, &size_, sizeof(int32_t));
// 从offset位置开始填充 size大小的实际数据
memcpy(storage + sizeof(int32_t), data_, size_);
}
}
2.3 BufferPoolManager
Buffer Pool主要为了”缓存”常用的磁盘页,这样就不用每次从磁盘中加载。另外由于内存有限,所以BufferPool肯定有一个限制,就是最多容纳多少Page。
那么当有新的磁盘页需要被加载的就涉及到置换的问题,使用算法呢? LRU?
当Buffer Pool中的磁盘页被修改之后,就形成了所谓的脏页,需要适时的落盘,它们是在什么时候落盘呢?
BusTub中的相关设计如下:
- 使用Page数组,来维护在内存中的磁盘页的具体信息,page_id、是否为脏页(is_dirty 这个很好理解,每次被修改之后会维护该标记,表示内存的中磁盘页和磁盘中的已经不一样),目前引用数(pin_count,用于判断当前页是否可以落盘,如果还被引用着,则不能直接落盘)
- 页表(page table)通过ExtendibleHashTable(一种动态的Hash算法,用于更好适应磁盘页的增减),来维护当前page在哪个位置

- 置换页面,最直观的就是LRU,但是这种没有考虑到偶发的使用,比如说MySQL如果Table scan,可能瞬间就将page table中填满了偶发使用的页,大大降低了缓存页命中率。MySQL采用的类似冷热页,加留存超过多长时间,由冷转热的思路,具体可以参照MySQL 8.0 15.5.1 Buffer Pool
而BusTub中采用了LRU-K,核心就是针对Page的最近K次访问,如果在指定区间,满足最少K次访问的页,距离越短所以访问频次相对越高;如果不足K次,则会在置换的时候,则会优先成为victim page。 关于LRU-K可以基于The LRU–K Page Replacement Algorithm关键词去搜索相关信息。
class BufferPoolManagerInstance : public BufferPoolManager {
Page *pages_;
/** Replacer to find unpinned pages for replacement. */
LRUKReplacer *replacer_;
}
2.2 查询优化(Query Optimization)
经过SQL解析之后会形成抽象语法树,然后通过binder,让解析的文本有实际意义。 所有节点都会变成PlanNode,也就是所谓的逻辑计划(LogicalPlan)
比如 where变成FilterPlanNode 然后经过优化器处理变成优化后的逻辑计划(Optimized LogicalPlan)。个人理解,RBO主要还是基于一些预定的规则,通过”树形变化”以减少查询过程中的数据扫描量、也就磁盘IO。
BusTub采用的是递归的方式,以逻辑计划AbstractPlanNodeRef(实际上就是抽象语法树的根节点)为基础,优化Children,如果有Children则继续,直到叶子节点停止。 在遍历的过程,需要对于指定位置节点进行判断,如果满足优化的要求,则进行处理。
比如说下面提到的筛选条件下推(filter condition push down)优化,就会在遍历到当前节点的为Filter且唯一Child为NestedLoopJoin的时候,尝试进行Filter节点移动。
auto Optimizer::OptimizeNLJAsHashJoinWithFilterPushDown(const AbstractPlanNodeRef &plan) -> AbstractPlanNodeRef {
std::vector<AbstractPlanNodeRef> children;
for (const auto &child : plan->GetChildren()) {
children.emplace_back(OptimizeNLJAsHashJoinWithFilterPushDown(child));
}
auto optimized_plan = plan->CloneWithChildren(std::move(children));
if (optimized_plan->GetType() == PlanType::Filter) {
BUSTUB_ENSURE(optimized_plan->children_.size() == 1, "Filter with multiple children?? Impossible!");
const auto &child_plan = optimized_plan->children_[0];
if (child_plan->GetType() == PlanType::NestedLoopJoin) {
...
}
...
}
}
下面针对几个比较典型的优化场景进行展开
2.2.1 筛选条件下推(filter condition push down)
这个经常被翻译为”谓词下推”,典型的场景就是两表关联之后再进行筛选。通过这个优化将join之后的filter,尝试提前到各表内部先去过滤,以减少联表过程中的数据(属于典型削IO的优化思路)。
以下面这个简单join + filter的SQL为例
CREATE TABLE t1(v1 int, v2 int); INSERT INTO t1 VALUES (100, 200); CREATE TABLE t2(v3 int, v4 int); INSERT INTO t2 VALUES (100, 1000);
explain SELECT * FROM t1 INNER JOIN t2 ON v1 = v3 where t1.v1 = 100;
简化之后的语法树
filter (FilterPlanNode)
||
join (NestedLoopJoinPlanNode)
/ \
t1 (SeqScanPlanNode) t2 (SeqScanPlanNode)
本优化需要做的就是,在可以进行下推的情况下。 将filter中的具体筛选条件基于是左表的还是右表的,进行拆分,将filter下移作为t1或t2的parent, 当然还可以进一步优化然后合并到作为t1或者t2的一部分。从树形结构上来看,从顶部向下移动,这也是该优化被称为下推的原因。
join (HashJoinPlanNode)
/ \
/
t1 (SeqScanPlanNode) filter (FilterPlanNode)
\
t2 (SeqScanPlanNode)
这样在SeqScanExecutor进行执行的时候,就需要检查是否满足相应的条件,满足才会返回一个tuple。 最后通过Explain查看执行计划,也可以很明显的看出,filter条件出现在了左边的SeqScan中。
=== PLANNER ===
Projection { exprs=[#0.0, #0.1, #0.2, #0.3] } | (t1.v1:INTEGER, t1.v2:INTEGER, t2.v3:INTEGER, t2.v4:INTEGER)
Filter { predicate=(#0.0=100) } | (t1.v1:INTEGER, t1.v2:INTEGER, t2.v3:INTEGER, t2.v4:INTEGER)
NestedLoopJoin { type=Inner, predicate=(#0.0=#1.0) } | (t1.v1:INTEGER, t1.v2:INTEGER, t2.v3:INTEGER, t2.v4:INTEGER)
SeqScan { table=t1 } | (t1.v1:INTEGER, t1.v2:INTEGER)
SeqScan { table=t2 } | (t2.v3:INTEGER, t2.v4:INTEGER)
=== OPTIMIZER ===
HashJoin { type=Inner, left_key=#0.0, right_key=#0.0 } | (t1.v1:INTEGER, t1.v2:INTEGER, t2.v3:INTEGER, t2.v4:INTEGER)
SeqScan { table=t1, filter=(#0.0=100) } | (t1.v1:INTEGER, t1.v2:INTEGER)
SeqScan { table=t2 } | (t2.v3:INTEGER, t2.v4:INTEGER)
在Spring 2022的项目中是没有实现这个优化的,笔者基于兴趣进行了扩展实现,后面会另开文章专门去讲解实现过程的思考和总结。
2.2.2 Join方式优化之NLJ To ILJ
Nested-Loop-Join 顾名思义就是每次Scan左边的记录,然后一次去遍历右边记录,看是否匹配。
几乎是存在于理论的join方式,实际应用出现可能是不可接受,特别是大表。一般的优化都会尝试从左边读取一批数据然后再去关联。
Index-Loop-Join就是要尝试优先关联的过程,如果检测到联表键,在右表中存在索引,就可以直接去索引表查询,这样就变成O(1)的查询复杂度了(这里忽略回表查询过程)。
比如说在MySQL中 还有Block Nested Loop Join(读取左边的表的时候,不再是单条,而是以批次的形式),8.0之后的,Hash Join彻底取代Block Nested Loop Join。
2.2.3 TopN优化之Order by + Limit
select * from table order by a desc limit 10;
像这种排序取前多少的,如果直接实现的话,就是将表所有记录进行内存排序然后取前10,但这对于有限的内存来说,肯定是一个很大的挑战。
假设在limit N中的这个N小于一定的值,比如说top 10、top 100、top 1000之类,也就是实际上取出来的值只有很少一部分,再加上需要从内存层面优化,自然会想到最小堆之内的优化。
也就是基于排序字段以及顺序,在内存中维护最小堆(比如说C++中的 std::priority_queue)。
再比如说Spark中,就会在不同的Executor分别基于最小堆(Java中 PriorityQueue实现)取出Top N,然后不同的Executor进行合并(类似于多路归并),取出N个TopN中的TopN。
为什么上面要提到一定范围呢? 因为如果limit数量和总数相差不大,比如说total: 100000、limit: 900000,又或者说total: 100, limit :10,前者的话几乎等同于全量排序,后者完全可以一个内存排序直接搞定,这就是有点类似于MySQL中二级索引和扫描全表的选择。
2.3 SQL执行(Query Execution)
2.3.1 逻辑计划 到 物理计划
经过SQL优化过程,我们得到了优化的逻辑执行加护(Opitmized AbstractPlanNode)。接下来就需要形成物理执行计划(AbstractExecutor)。这个过程几乎是所有数据库都会有的流程。 不同的点就是 不同的数据库基于不同的优化策略,就采用不同的方法将逻辑计划 转换成 物理计划。
BusTub中基本一一映射的,比如说SeqScanPlanNode,就会直接变成SeqScanExecutor。
// Create a new sequential scan executor
case PlanType::SeqScan: {
return std::make_unique<SeqScanExecutor>(exec_ctx, dynamic_cast<const SeqScanPlanNode *>(plan.get()));
}
比如说Spark SQL中在计算count(distinct)就会拆分成 两次Group By, 这个在执行计划上肯定有体现的。以下面这个简单, 分组取去重数为例:
select userId, count(distinct name) from user group by userId
逻辑计划:
Aggregate [userId#10], [userId#10, count(distinct name#11) AS count(DISTINCT name)#38L]
+- SubqueryAlias user
+- View (`user`, [userId#10,name#11,age#12])
+- Project [_1#3 AS userId#10, _2#4 AS name#11, _3#5 AS age#12]
+- LocalRelation [_1#3, _2#4, _3#5]
最终的物理计划:
AdaptiveSparkPlan isFinalPlan=false
+- HashAggregate(keys=[userId#10], functions=[count(distinct name#11)], output=[userId#10, count(DISTINCT name)#38L])
+- Exchange hashpartitioning(userId#10, 200), ENSURE_REQUIREMENTS, [id=#27]
+- HashAggregate(keys=[userId#10], functions=[partial_count(distinct name#11)], output=[userId#10, count#43L])
+- HashAggregate(keys=[userId#10, name#11], functions=[], output=[userId#10, name#11])
+- Exchange hashpartitioning(userId#10, name#11, 200), ENSURE_REQUIREMENTS, [id=#23]
+- HashAggregate(keys=[userId#10, name#11], functions=[], output=[userId#10, name#11])
+- LocalTableScan [userId#10, name#11]
从最后的物理计划来看,可以明显看到多次HashAggregate,中间还有一次partial_count,简而言之就是实际的执行较逻辑计划发生了很大的变化。
2.3.2 关于执行模式(Processing Models)
火山模型(Volcano model) 也叫做迭代器模型(Iterator model),如果联想到编程语言,比如说Java中的Iterator,就能更好的理解基本的原理了。
这种模型极大了简化了SQL执行实现,每一个算子执行需要实现三个基本方法:
- 初始化(一般会定义为open / init之类的) – 进行算子初始化相关的工作
- 产出行(一般会定义为next) – 当前算子在产生tuple的时候,如果有child,就会依次迭代调用。该方法会不断循环调用,知道返回值为false,说明该算子已经不能再产生tuple。 所以算子在初始化的时候,一般会传入下游的算子作为参数,这样在调用自己的next方法时,检测到有child,则会先调用
- 清理方法(一般会定义为close) – 一些资源清理的工作,BusTub项目中并没有使用到该类
可以看到这种模式虽然实现起来简化简单,但是有几个明显的问题:
- 每次next返回单个tuple,意味着next方法会频繁调用。next函数一般是虚函数,需要各种算子自行实现,在C++中虚函数会降低CPU的分支预测能力,进一步降低了执行效率
- 由于处理方式导致了较差的局部性(locality),例如Scan,按照火山模型,一次一行,但当真实scan一行时,其后面的几行都会被cache到(这里主要指的是CPU cache line,比如说L1 cache),但无法直接使用这个cache的数据,因为要等到scan的第一行完成上级多个operator的next处理后,才可以进行下一行。
2.4 事务管理以及并发控制(TODO)
这部分在Spring 2022的课程对应的是Project 4的内容,不过因为时间问题以及对应锁机制研究并不是很深,所以这部分会进一步熟悉锁机制之后进行补充很完善。
3. 总结
总体而言,BusTub还是一个非常雏形的关系型数据库,不过尽管有很多地方还不完善,但如果基于课程完成项目一定能对于关系型数据库的底层原理有更深的了解,个人印象比较深的是BufferPoolManager设计、索引”树”的维护(通过这部分,再来理解为什么索引不不是越多越好就会更加清晰)、查询执行等。
于个人而言,更多的感受到了数据库系统工程的复杂,有很多分支领域需要花时间去研究,比如说存储设计、查询优化、查询调度之类。在学习的过程也更加感受到了数据库的魅力,所以工作之余学习很多相关的数据库底层原理的知识,基于此才有了数据库综述这个系列,想要通过这一系列文章来形成自己研究数据库的方法论。