Memcached是一个高性能的分布式缓存系统,但Memcached的集群与一般的服务器端集群还不太一样,最显著的一点就是Memcached的各台服务器之间并没有通讯机制,也就是如果一台服务器挂了,其它的服务根本就不知道。
Memcached实际上没有集群的概念,它的分布式主要是靠客户端实现的,客户端决定采用什么算法将键均匀的分布到服务器上并且在服务器增加或减小的时候重算哈希(Rehash)。这里借助Memcached的Java客户端Xmemcached来介绍两种实现。
1.Xmemcache对于连接的抽象
val addrs = List("127.0.0.1:11211", "127.0.0.1:11311")
val builder = {
val clientBuilder =
new XMemcachedClientBuilder(AddrUtil.getAddresses(addrs.mkString(" ")))
// 默认的SessionLocator是ArrayMemcachedSessionLocator
clientBuilder.setSessionLocator(new KetamaMemcachedSessionLocator)
clientBuilder.setCommandFactory(new BinaryCommandFactory)
clientBuilder
}
val client = builder.build
上面的代码构建了一个Memcached客户端,由于Xmemcached将每一次服务器连接抽象成了Session,所以命令行里会输出如下的语句:
...
com.google.code.yanf4j.core.impl.AbstractController Add a session: 127.0.0.1:11211
com.google.code.yanf4j.core.impl.AbstractController Add a session: 127.0.0.1:11311
...
当我们构建客户端的时候传入了多个服务器端地址,那么在存储的时候就会涉及到选址的问题。net.rubyeye.xmemcached.MemcachedSessionLocator的多个子类提供了这一问题的解决方案,包括一致性哈希。默认情况下使用的是net.rubyeye.xmemcached.impl.ArrayMemcachedSessionLocator。 以下分别对默认和一致性哈希的情况进行解析(代码是基于Scala的简化版)。
2.哈希取余 – ArrayMemcachedSessionLocator
// 确定Hash策略
private def getHash(key: String, addrSize: Int) = {
val hash = key.hashCode // NATIVE_HASH
hash % addrSize
}
def getSessionByKey(key: String) = {
// 客户端连接之后会生成List[List[Session]] ,这里简化为List[List[String]]
// scala> new InetSocketAddress("127.0.0.1", 11211)
// res7: java.net.InetSocketAddress = /127.0.0.1:11211
// Memcached是基于TCP连接的,内部会构造InetSocketAddress
val sessions: List[List[String]] = List(List("/127.0.0.1:11211"), List("/127.0.0.1:11311"))
val start = getHash(key, sessions.size)
val sessionListOpt: Option[List[String]] = {
sessions.zipWithIndex.find {
case (sess, index) => index == start
}.map(_._1)
}
sessionListOpt.map { sessionList =>
sessionList.zipWithIndex.find {
case (se, index) => index == Random.nextInt(sessions.size)
}.map(_._1)
}.getOrElse {
// 重算哈希的相关机制, 具体见源码实现
Some("")
}
}
这种实现有一个问题,就是当Server节点增加或者是减小的时候,很多缓存会失效(如果节点由N变到N + 1那么最坏的情况下有N / (N + 1)的数据受到影响), 间接对于数据库带来压力。
3.一致性哈希 – KetamaMemcachedSessionLocator
一致性哈希就是要通过某种哈希算法来更均匀的分布key,以使得在服务器节点变化时,受影响的数据更小。
简单来说就是有一个环(英文中叫Continuum),环上的每一点对应(0 ~ (2 ^ 32))之间的一个整数(如下简略图所示),通过某种哈希算法将服务器地址与环上的整数相对应,一个服务器大概对应100 ~ 200个整数(magic number)。将要存储的Key也以某种方式进行哈希,放到环上相应的位置。如果没有找到对应的点,则按照顺时针方向往前,碰到的第一个点对应的服务器就是该Key被存储的服务器(当然还涉及到一些哈希冲突什么的)。
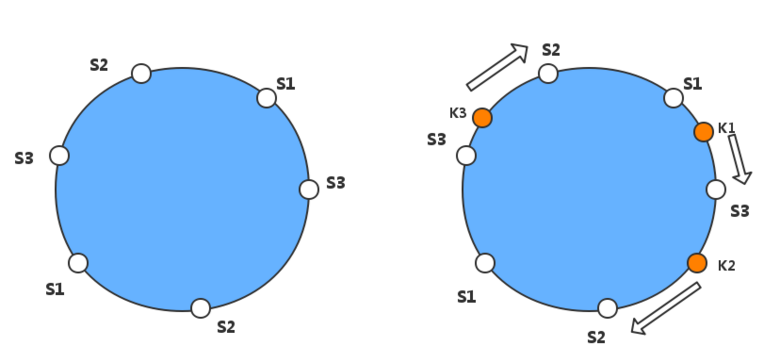
这种情况下如果Memcache集群中加入一个节点,受影响的数据量为:
# N为原节点数,X为新增加的节点数
影响百分比 = X / (N + X)
前面我们提到了SessionLocator,它的子类net.rubyeye.xmemcached.impl.KetamaMemcachedSessionLocator就是用来实现将Server节点地址映射到环上的。以下是简化版代码,具体实现可参考源码。
import java.security.MessageDigest
def buildMap = {
// 基于红黑树的实现
var sessionMap = TreeMap[Long, List[String]]()
val memcachedServerAddrs = List("/127.0.0.1:11211", "/127.0.0.1:11311")
// Xmemcached每个Server默认映射的是160个点
memcachedServerAddrs.foreach { sockStr =>
(0 until 40).foreach { num =>
val digest = HashAlgorithm.computeMd5(sockStr + "-" + num) // 长度为16的Array[Byte]
(0 until 4).foreach { h =>
val k = (digest(3 + h * 4) & 0xFF).toLong << 24 |
(digest(2 + h * 4) & 0xFF).toLong << 16 |
(digest(1 + h * 4) & 0xFF).toLong << 8 |
digest(h * 4) & 0xFF
sessionMap = sessionMap + {
sessionMap.get(k).map { sessions =>
k -> (sockStr :: sessions)
}.getOrElse {
k -> (sockStr :: Nil)
}
}
}
}
}
sessionMap
}
节点散列的关键就在于计算K的那一行,但比较尴尬的是由于水平有限,目前还不了解为什么结合布尔操作和位移操作会更均匀的分布。
当Server节点分布在环上之后,接下来需要做的就是按照开始提到的将键映射到相应的节点上。关于这个过程的具体实现在net.rubyeye.xmemcached.impl.MemcachedConnector中,因为最终客户端会向Memcached服务器端发送各种请求,在Xmemcached中被封装成了Command。
public Session send(final Command msg) throws MemcachedException {
MemcachedSession session = (MemcachedSession) this.findSessionByKey(msg
.getKey());
....
}
public final Session findSessionByKey(String key) {
return this.sessionLocator.getSessionByKey(key)
}
getSessionByKey的完整实现可以参见KetamaMemcachedSessionLocator,以下为简化版的实现。
def ketamaHashKey(key: String) = {
val keyBytes = HashAlgorithm.computeMd5(key)
// 取前四个byte进行操作进行哈希操作
(keyBytes(3) & 0xFF).toLong << 24 |
(keyBytes(2) & 0xFF).toLong << 16 |
(keyBytes(1) & 0xFF).toLong << 8 |
(keyBytes(0) & 0xFF).toLong
}
def getSessionByKey(hash: Long) = {
val memcachedServerAddrs = 3
val sessionMap = buildMap() // 调用上面的将服务器映射到环的方法
(sessionMap.get(hash).fold({
val nextKey = sessionMap.from(hhash).firstKey
sessionMap.get(nextKey)
})(sessions => Some(sessions))).map(session =>
session(Random.nextInt(memcachedServerAddrs)))
}
对上面的实现的简单解释:
如果哈希值没有对应的服务器地址,则顺着环往下找; 根据红黑树实现的话,应该是找到大于等于当前Key的最小Key,在Java中TreeMap有ceilingKey和floorKey等方法用于锁定相应的Key,Scala没有提供对应的实现,但是提供了from和to, 返回的整个子树而不是某个Key所以我们先可以找到对应的子树 然后找到最大值即可。当然在源码的实现中,还涉及到重试的机制(第一次Key找不到对应的服务器地址,则重算哈希再进行寻找)。获取List[Session]后,由于可能是多个服务器地址所以随机取一个存放即可。
接下来的可以做一个小小的验证,使用buildMap打印出Hash值对应的服务器地址:
Key: 42540355 Value: /127.0.0.1:11211
Key: 52869756 Value: /127.0.0.1:11311
Key: 66469197 Value: /127.0.0.1:11311
Key: 96001103 Value: /127.0.0.1:11311
然后,往Memcached中添加Key的时候使用ketamaHashKey打印出相应的Hash值,在buildMap的结果中寻找最接近的哈希值锁定服务器地址,然后通过telnet连接Memcached服务器去进一步验证。自己写完之后验证了一下,没毛病。